































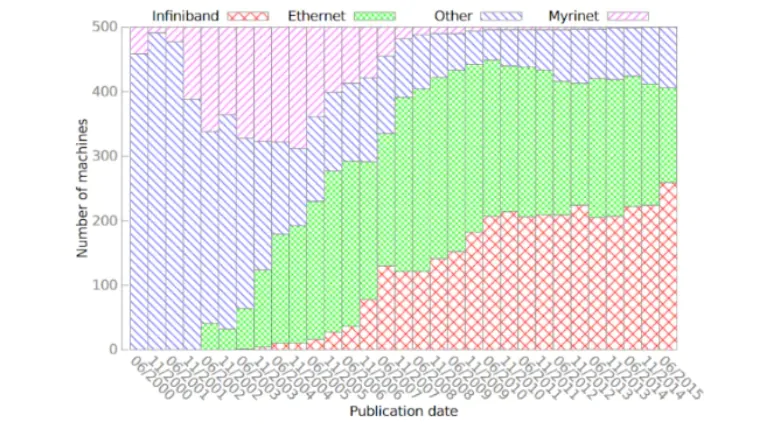
As the development of high-performance computing (HPC) systems continues to evolve, the demand for efficient and robust networking solutions becomes paramount. Initially, specialized network solutions such as Myrinet, Quadrics, and InfiniBand were preferred over Ethernet solutions to overcome Ethernet's limitations, enhance bandwidth, reduce latency, and improve congestion control. However, the introduction of the RoCE (RDMA over Converged Ethernet) protocol by the IBTA in 2010, and its subsequent upgrade to RoCEv2 in 2014, has significantly improved network bandwidth and performance. This has sparked renewed interest in high-performance network solutions compatible with traditional Ethernet, reversing the declining trend of Ethernet usage in the top 500 HPC clusters and maintaining its critical role in these environments.
1. Why High-Performance Networks Are Necessary
- The Critical Importance of Networks
-
- Significance of Network Connections: Networks interconnect all nodes, enabling various services and remote user operations. Without network connectivity, the entire system ceases to function.
- Complexity of Networks: Unlike business systems which may operate at a single server or cluster level, network systems function at the data center level, involving intricate network business logic across the entire data center.
- Severity of Network Failures: Failures in compute or storage servers are localized, whereas network failures can disrupt the entire data center, leading to significant outages. Even minor network issues can render the entire data center inoperable.
- Increasing East-West Traffic
In large-scale cluster computing, east-west traffic has surged due to complex data center computing scenarios and system decomposition. This has rapidly increased network bandwidth requirements from 10G and 25G to 100G, and even 200G.
- Short Transmission Distance and System Stack Latency
Data center networks have shorter transmission distances than metropolitan or global interconnected networks, emphasizing the latency introduced by system stacks.
- CPU Performance Bottleneck and Network Processing Delay
While network bandwidth has increased rapidly, CPU performance has hit a bottleneck. The CPU resource consumption for network stack processing has escalated, further increasing delays.
- Latency Sensitivity in Cross-Server Calls
Software services require cross-server remote calls to have low latency, comparable to local calls, making latency a critical factor.
2. Network Congestion Control
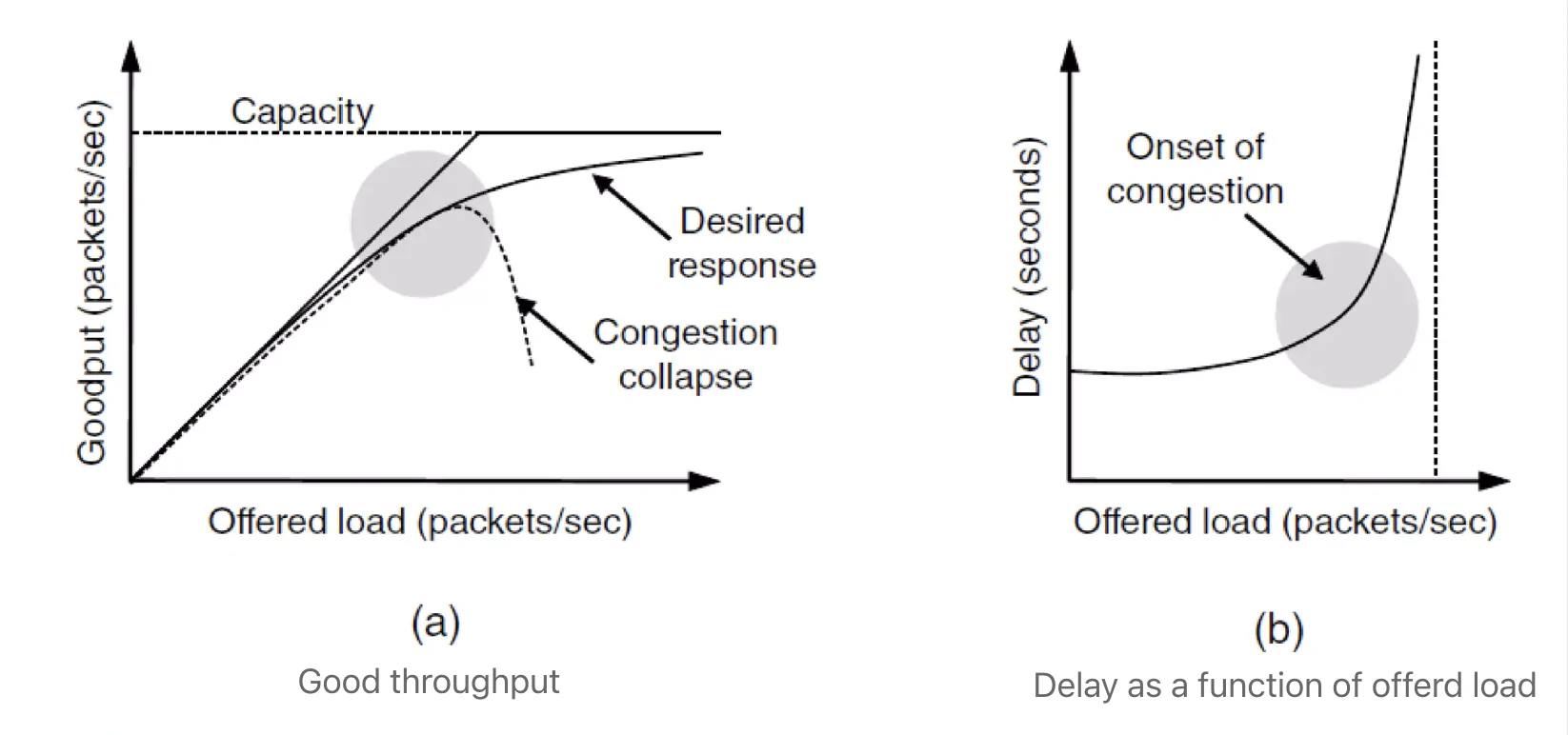
Network congestion occurs when an excessive number of data packets lead to delays and packet loss due to timeouts, reducing transmission performance. High-performance networks aim to maximize network capacity utilization, providing low-latency transmission while avoiding congestion. When the number of data packets sent by a host is within the network's capacity, the packets delivered grow proportionally to those sent. However, as the load approaches the network's limit, sudden bursts of traffic can cause congestion collapse. When the packet load nears the maximum capacity, latency spikes sharply, resulting in network congestion.
Congestion control (CC) ensures the network can handle all incoming traffic, addressing a global issue. In contrast, flow control ensures fast senders do not overwhelm receivers, addressing an end-to-end issue.
Congestion Control Strategies:
- Higher Bandwidth Networks: Increasing network bandwidth to accommodate more traffic.
- Traffic-Aware Routing: Customizing routing based on traffic patterns.
- Load Reduction: Implementing admission control to manage load.
- Feedback to Source: Providing feedback to sources to suppress traffic.
- Packet Discarding: As a last resort, discard packets that cannot be transmitted.
Principles of Congestion Control Algorithms:
- Optimized Bandwidth Allocation: Efficiently utilizing available bandwidth while avoiding congestion.
- Fair Bandwidth Allocation: Ensuring fairness in bandwidth distribution, balancing large and small data flows.
- Rapid Convergence: Quickly adapting to changes in network conditions to prevent congestion.
3. Introduction to the RoCE Protocol
RoCE (RDMA over Converged Ethernet) is a cluster network communication protocol that enables remote direct memory access over Ethernet. By offloading packet transmission and reception tasks to network adapters, RoCE reduces the need for system transitions to kernel mode, minimizing overhead and significantly lowering Ethernet communication latency. Additionally, RoCE optimizes CPU resource utilization during communication, reduces network congestion, and enhances bandwidth efficiency. The RoCE protocol includes two versions: RoCE v1 and RoCE v2.
RoCE v1 Protocol
RoCE v1 operates at the link layer, retaining the InfiniBand interface, transport layer, and network layer, but replacing the IB link and physical layers with Ethernet equivalents. In RoCE data frames, the Ethernet type field is set to 0x8915, as designated by IEEE, clearly identifying the frames as RoCE packets. However, RoCE v1 does not use the Ethernet network layer, lacking IP fields, thus restricting routing within Layer 2 networks.
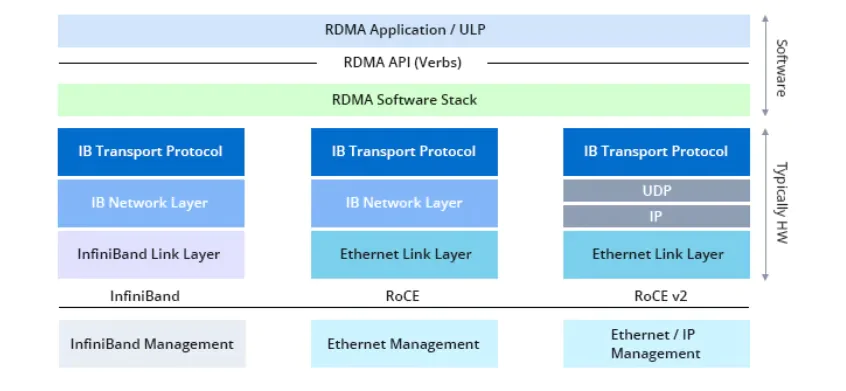
RoCE v2 Protocol
Building on RoCE v1, RoCE v2 optimizes the protocol by integrating the Ethernet network layer and using the UDP protocol at the transport layer, replacing the InfiniBand network layer. RoCE v2 leverages the DSCP and ECN fields in IP datagrams for congestion control, allowing RoCE v2 packets to be routed at Layer 3, thus providing better scalability. RoCE v2 has completely supplanted the original RoCE protocol, making "RoCE" typically refer to RoCE v2 unless specifically denoted as RoCE v1.
4. Lossless Network and RoCE Congestion Control Mechanism
Ensuring seamless transmission of traffic in RoCE networks is crucial. In RDMA communication, packets must arrive at their destination without loss and in the correct order. Any packet loss or out-of-order arrival requires a "go-back-N"(GBN) retransmission, and subsequent expected packets should not be stored in the buffer.
RoCE employs a dual congestion control mechanism: initially, Data Center Quantized Congestion Notification (DCQCN) is used for gradual deceleration, followed by PFC (Priority Flow Control) to pause transmission. Although these are distinct strategies, they are often considered two phases of congestion control.
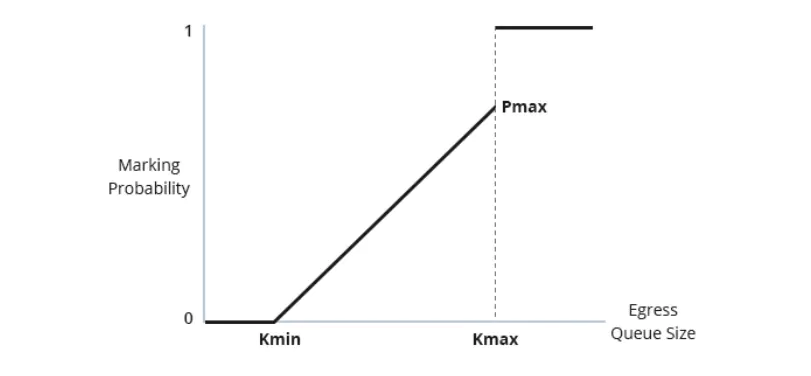
In applications involving many-to-one communication, congestion frequently occurs, evidenced by the rapid increase in the size of the transmit buffer queue at the switch port. Without control, this can lead to buffer saturation and packet loss. Initially, when the switch detects that the total size of the transmit buffer queue at a port has reached a certain threshold, it marks the ECN (Explicit Congestion Notification) field in the IP layer of RoCE packets. Upon receiving this packet, if the receiver observes the marked ECN field, it sends a Congestion Notification Packet (CNP) to the sender, prompting it to reduce the send rate.
Not all packets are marked when the ECN threshold is reached. Two parameters, Kmin and Kmax, play critical roles. No marking occurs when the congestion queue length is below Kmin. When the queue length is between Kmin and Kmax, the probability of marking increases with the queue length. If the queue length exceeds Kmax, all packets are marked. The receiver does not send a CNP for every received packet with an ECN mark but sends a CNP once per interval if such packets are received. This method allows the sender to adjust its sending rate based on the number of received CNPs, avoiding excessive packet marking and loss. This dynamic congestion control mechanism provides more effective traffic regulation and reliable data transmission.
When network congestion worsens, and the switch detects that the transmit queue length of a specific port has reached a higher threshold, it sends a PFC frame to the upstream sender. This operation pauses data transmission until the congestion in the switch is alleviated. Once congestion is relieved, the switch sends a PFC control frame to the upstream sender, indicating that transmission can resume. PFC flow control supports pausing traffic on different channels and can adjust the bandwidth ratio of each channel relative to the total bandwidth. This configuration allows pausing traffic on one channel without affecting data transmission on other channels.
5. RoCE & Soft-RoCE
While most high-performance Ethernet NICs now use the RoCE protocol, some NICs do not support RoCE. To bridge this gap, the open-source project Soft-RoCE, initiated by IBIV, Mellanox, and their partners, allows nodes without RoCE support to communicate with RoCE-supported nodes using Soft-RoCE. This combination enhances overall performance and scalability, particularly in data centers.
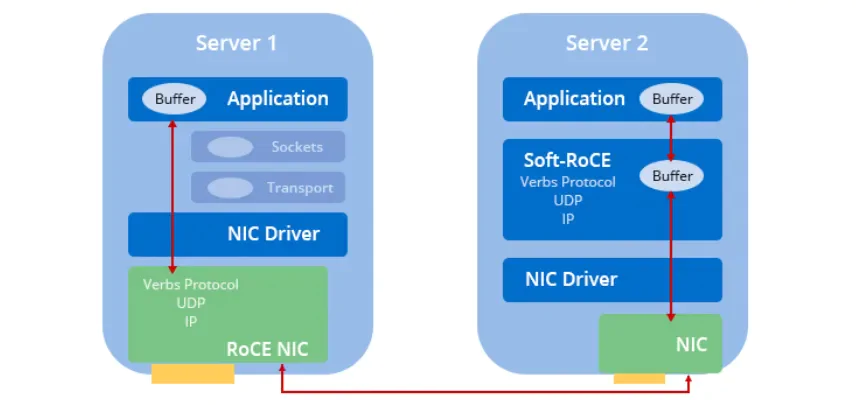
6. Challenges of Implementing RoCE in HPC Environments
Basic Requirements of HPC Networks
High-performance computing (HPC) networks depend on two fundamental premises: low latency and the ability to maintain low latency under dynamic traffic conditions. RoCE is specifically designed to address low latency by offloading network operations to the NIC, thereby reducing CPU utilization and achieving low latency. However, maintaining low latency in dynamic traffic environments is challenging and primarily focuses on congestion control. The complexity of highly dynamic HPC traffic patterns can adversely affect RoCE performance.
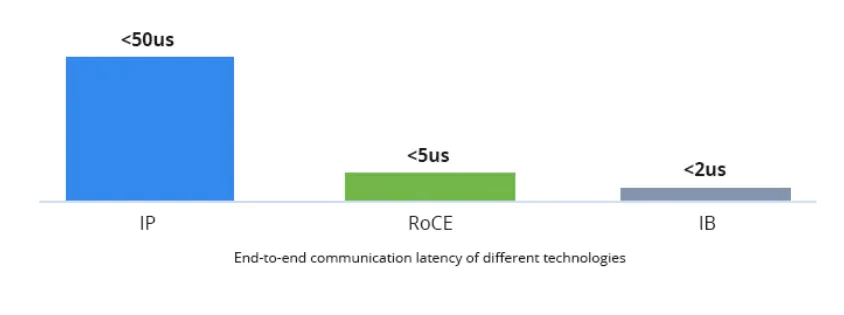
Low Latency with RoCE
Compared to traditional TCP/IP networks, both InfiniBand and RoCEv2 bypass the kernel protocol stack, significantly enhancing latency performance. Empirical tests show that bypassing the kernel protocol stack can reduce end-to-end latency within the same cluster from 50µs (TCP/IP) to 5µs (RoCE) or even 2µs (InfiniBand).
RoCE Packet Structure
To illustrate the overhead of RoCE, consider sending a 1-byte data packet. The encapsulation overhead includes:
- Ethernet Link Layer: 14-byte MAC header + 4-byte CRC
- Ethernet IP Layer: 20 bytes
- Ethernet UDP Layer: 8 bytes
- IB Transport Layer: 12-byte Basic Transport Header (BTH)
- Total: 58 bytes
For InfiniBand, sending a 1-byte data packet includes:
- IB Link Layer: 8-byte Local Route Header (LHR) + 6-byte CRC
- IB Network Layer: 0 bytes (link layer’s Link Next Header (LNH) field indicates no network layer for a 2-layer network)
- IB Transport Layer: 12-byte BTH
- Total: 26 bytes
In custom networks, the packet structure can be further simplified. For example, the Tianhe-1A mini packet (MP) header comprises 8 bytes. The inherent complexity of Ethernet's underlying structure poses a barrier to applying RoCE in HPC environments. Ethernet switches in data centers typically need features like SDN and QoS, which add extra costs. The compatibility of these features with Ethernet and RoCE and their impact on RoCE performance is a concern.
7. Challenges in RoCE Congestion Control
RoCE's congestion control mechanisms face specific challenges, potentially hindering the maintenance of low latency under dynamic traffic conditions. PFC relies on pause control frames to prevent receiving too many data packets, which can lead to packet loss. Unlike credit-based methods, PFC often results in lower buffer utilization, posing challenges for switches with limited buffers and generally correlating with lower latency. In contrast, credit-based methods provide more precise buffer management.
Data Center Quantized Congestion Notification (DCQCN) in RoCE, similar to InfiniBand congestion control, uses backward notification, passing congestion information to the destination, which then informs the sender to adjust the transmission rate. RoCE follows a set of fixed deceleration and acceleration strategy formulas, while InfiniBand allows custom strategies, offering greater flexibility. Although default configurations are commonly used, having customization options is beneficial.
During testing, a CNP is generated at most every N=50µs. The feasibility of reducing this value is uncertain. In InfiniBand, the minimum CCTI_Timer setting can be 1.024µs, but achieving such a small value in practice is still unconfirmed. Directly returning congestion information from the congestion point to the source, known as forward notification, is understood within Ethernet's limitations. However, the specific reasons InfiniBand did not adopt this method remain unclear.
8. RoCE Applications in High-Performance Computing
The latest American supercomputers use Slingshot networks, an enhanced Ethernet solution designed to address specific RoCE limitations. Slingshot networks utilize Rosetta switches, compatible with traditional Ethernet, to provide network enhancements when both ends of a link support specialized devices such as NICs and Rosetta switches. These enhancements include minimizing IP packet frame sizes to 32 bytes, sharing queue occupancy information with adjacent switches, and implementing improved congestion control.
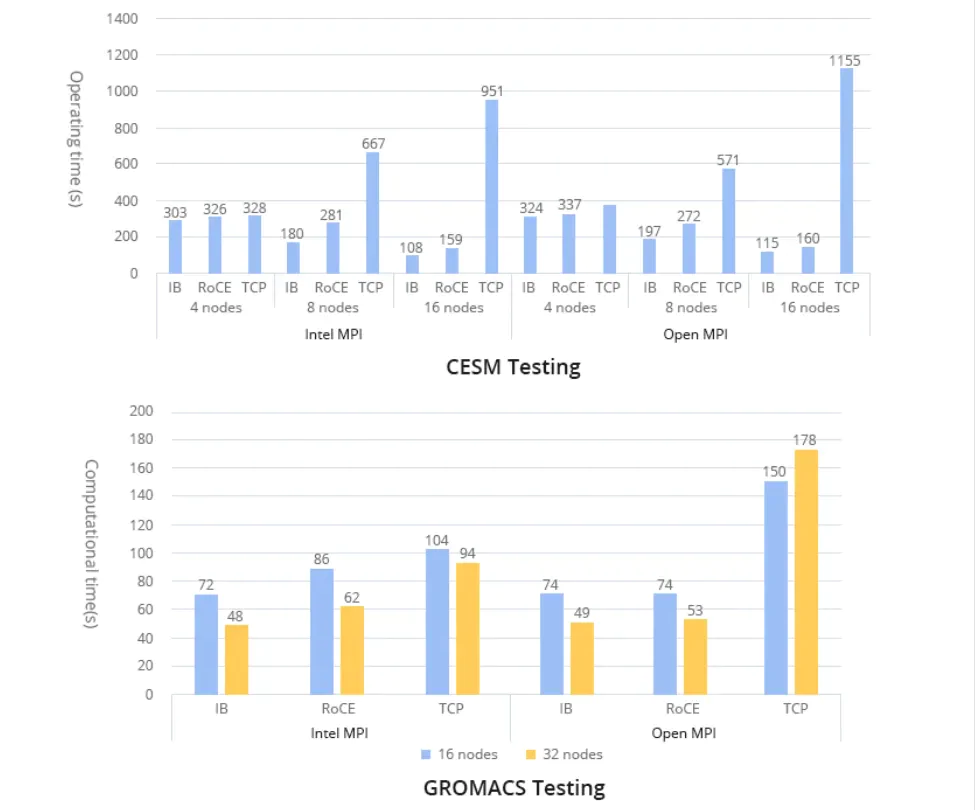
While the average switch latency in Slingshot networks is 350ns, comparable to high-performance Ethernet switches, it is lower than InfiniBand and some proprietary supercomputer switches, such as those in Cray XC supercomputers. In practical applications, Slingshot networks have demonstrated reliable performance. The "In-Depth Analysis of Slingshot Interconnect" primarily compares it with previous Cray supercomputers rather than directly with InfiniBand. Additionally, applications like CESM and GROMACS have been tested using low-latency 25G Ethernet and higher-bandwidth 100G Ethernet. Despite the fourfold difference in bandwidth between these networks, the test results provided valuable performance comparisons.
9. Conclusion
As AI data center networks rapidly evolve, choosing the right solution is critical. Traditional TCP/IP protocols no longer meet the high-performance network demands of AI applications. RDMA technologies, particularly InfiniBand and RoCE, have emerged as preferred network solutions. InfiniBand has demonstrated exceptional performance in high-performance computing and large-scale GPU clusters. In contrast, RoCE, as an Ethernet-based RDMA technology, offers enhanced deployment flexibility.
NADDOD offers comprehensive network solutions for RoCE and InfiniBand architectures, ensuring high-speed, low-latency, and reliable performance for HPC and AI-driven data centers. NADDOD leverages advanced manufacturing capabilities and a strong R&D foundation to provide a range of high-speed transceivers, DACs, and AOCs, meeting diverse networking needs. NADDOD's commitment to quality and innovation ensures robust, scalable, and efficient network infrastructures, supporting the future growth of data-intensive applications and the AI-driven transformation of industries.
Explore NADDOD’s offerings to enhance your HPC and data center performance with cutting-edge RoCE and InfiniBand solutions.


 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1What is High-Performance Computing (HPC)?
- 2Comprehensive Guide to High-Performance Networking
- 3PFC Flow Control Technology and Challenges in RoCEv2 Network Deployment
- 4NADDOD 1.6T XDR Infiniband Module: Proven Compatibility with NVIDIA Quantum-X800 Switch
- 5Vera Rubin Superchip - Transformative Force in Accelerated AI Compute







