
































With the rise of large-scale models, the size of GPU clusters has expanded significantly. Given the limited performance improvements in single-chip computing, the overall performance can only be enhanced by scaling up. Clusters with thousands or even tens of thousands of GPUs have become mainstream, and there are plans for clusters with hundreds of thousands or millions of GPUs in the next 3-5 years.
Cluster computing networks can be categorized into North-South traffic (external network traffic) and East-West traffic (internal network traffic). The number of network connections in a cluster is defined as S = N × ( N − 1 ) (where N is the number of nodes). This high node count explains why East-West traffic accounts for over 90% of data center traffic. Additionally, the increase in North-South traffic due to expanding system sizes has led to an exponential growth in the network bandwidth required by data centers.
In 2019, NVIDIA acquired Mellanox, establishing itself as a leader in high-performance networking with its advanced capabilities in InfiniBand and ROCEv2. As of June 2024, NVIDIA's dominant position is reflected in its stock price. Competitors like AWS and Alibaba Cloud have introduced their high-performance network protocols and products, creating a highly competitive industry landscape. High-performance networking is a crucial battleground, and the future leaders in this space are yet to be determined.
This article provides an introduction and analysis of high-performance networking technologies from a hardware-software integration perspective, offering a comprehensive understanding of high-performance networking.
1. Overview of High-Performance Networks
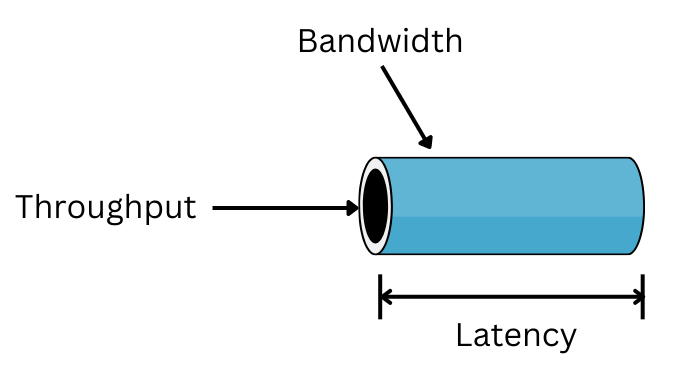
1.1 Network Performance Parameters
Network performance is primarily measured by three parameters: bandwidth, throughput, and latency. Bandwidth refers to the amount of data that can be transmitted within a specific period. However, high bandwidth alone does not guarantee optimal network performance, as factors like packet loss, jitter, or delay can affect throughput. Throughput indicates the actual amount of data that can be sent and received within a specific period, helping users understand how many data packets successfully reach their destination. High-performance networks require accurate delivery of data packets; excessive packet loss can degrade network performance. Latency is the time it takes for a data packet to travel from source to destination, typically measured as the round-trip time. High latency can result in unstable and laggy services, which is critical for applications like video conferencing.
Another crucial metric is PPS (Packets Per Second), which measures the number of data packets transmitted per second. Many network devices achieve line-rate performance with large packets but suffer significant performance drops with small packets (64 bytes) due to insufficient PPS capacity. Ideally, line-rate performance should be achievable even with the smallest packets. High-performance networking aims to achieve maximum throughput (approaching network bandwidth) with low latency and jitter, regardless of packet size or network node. These parameters are interrelated, and practical systems must balance them to optimize overall performance.
1.2 Complex Network Layering
The OSI model defines a seven-layer network protocol, but the practical TCP/IP model used in engineering applications typically has five layers: Physical, Data Link, Network, Transport, and Application layers. The Physical and Data Link layers are usually implemented in hardware, while the Network, Transport, and Application layers are implemented in software.
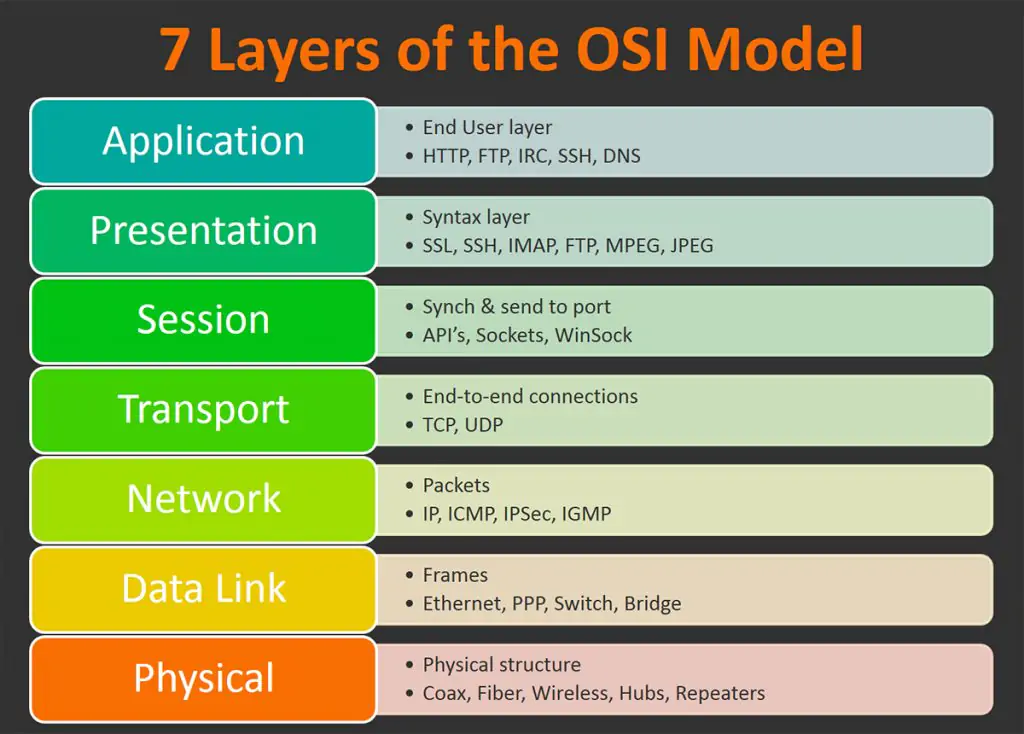
The TCP/IP protocol suite, used in computer networks, includes core protocols like TCP (Transmission Control Protocol), IP (Internet Protocol), and UDP (User Datagram Protocol).
Ethernet, designed for local area network (LAN) communication, specifies physical layer connections, electronic signals, and medium access control protocols, making it the most widely used network technology today.
Data center networks are more complex and are divided into Overlay and Underlay networks. Functionally, cloud computing data center networks can be divided into three layers: the Physical Layer (Underlay network), which provides foundational physical network connections; the Virtual Network Layer (Overlay network), which builds virtual networks on top of the physical network; and the Application Layer, which includes various user-visible network services such as access gateways and load balancing, as well as other network-dependent applications. A physical data center is a LAN that can be segmented into thousands of virtual private networks (VPNs) using Overlay networks, requiring network security mechanisms to achieve high-performance cross-domain access.
Based on network processing logic, networking can be divided into three parts: Packet Encapsulation/Decapsulation, where business data is encapsulated into the specified network format for transmission and decapsulated upon reception; Network Packet Processing, which includes additional encapsulation for Overlay networks, packet identification by firewalls, and packet encryption/decryption; and Packet Transmission, the core focus of high-performance networking.
1.3 The Need for High-Performance Networks
High-performance networks are essential due to their critical role in modern data centers, where network connectivity links all nodes and facilitates remote operations. The complexity of data center networks, which involve constructing intricate network logic on a large scale, means that any network failure can be catastrophic, affecting the entire data center. The demand for higher bandwidth has surged with the rapid expansion of data centers and the increasing East-West traffic, pushing requirements from 10G and 25G to 100G and beyond. Additionally, the short transmission distances within data centers highlight the latency of the system stack, further exacerbated by CPU performance bottlenecks as network bandwidth grows. The latency sensitivity in cross-server calls demands near-local call performance, making high-performance networks vital to ensure low-latency and efficient remote server interactions.
1.4 Network Congestion Control
Network congestion occurs when excessive data packets cause delays and packet loss, degrading transmission performance. High-performance networks aim to fully utilize network capacity while minimizing latency and avoiding congestion. Congestion control ensures the network can handle incoming traffic by addressing the issue globally, while flow control focuses on end-to-end transmission to prevent senders from overwhelming receivers. Effective congestion control strategies include higher bandwidth networks, traffic-aware routing, load reduction through admission control, feedback mechanisms to suppress source-end traffic, and, if necessary, packet dropping. The goal is to optimize bandwidth allocation to avoid congestion, ensure fairness across transmissions, and achieve rapid convergence of the congestion control algorithm, maintaining efficient and reliable network performance.
1.5 Equal-Cost Multi-Path Routing (ECMP)
The CLOS architecture is a topology used to build high-performance, high-reliability data center networks. Due to increased East-West traffic, data center networks often adopt the CLOS structure to meet high-bandwidth demands. The CLOS architecture provides multiple network paths between hosts, forming the foundation for high-performance and reliable networking.
Effectively utilizing network topology, path resources, and bandwidth resources to balance network load, distributing data streams across different paths to avoid congestion and improve resource utilization within the data center is increasingly important. ECMP (Equal-Cost Multi-Path routing) is a hop-by-hop flow-based load balancing strategy. When a router identifies multiple optimal paths to the same destination, it updates the routing table with multiple rules for that destination, each corresponding to different next hops. These paths can be used simultaneously to forward data, increasing bandwidth.
Common ECMP path selection strategies include hashing (selecting paths based on the hash of the source IP address), round-robin (distributing flows across paths in a round-robin fashion), and path weight (allocating flows based on path weight, with higher-weight paths receiving more flows). In data centers with bursty traffic, where large flows (elephant flows) and small flows (mice flows) coexist, careful consideration of load balancing strategies is necessary. Although ECMP is simple and easy to deploy, several issues need attention.
2. TCP/IP High-Performance Networking Technologies
2.1 TCP/IP Stack Offload
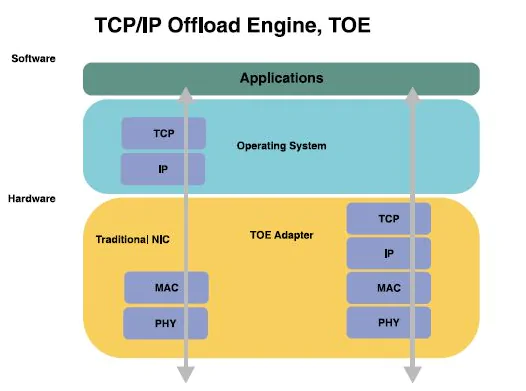
The TCP/IP protocol stack, primarily composed of Ethernet, TCP/IP, and Socket systems, can be optimized through offloading to enhance network performance. Offloading can be categorized into two types: partial TCP feature offload and full TCP/IP stack offload (TOE).
Partial TCP feature offload leverages NIC hardware to handle specific TCP functions, reducing the CPU load. Examples include:
TCP Segmentation Offload (TSO): Segments TCP packets using NIC hardware.
UDP Fragmentation Offload (UFO): Handles large UDP packets, performing fragmentation in hardware.
Large Receive Offload (LRO): Aggregates multiple received TCP packets into larger ones.
Receive Side Scaling (RSS): Distributes network flows into different queues, assigning each to multiple CPU cores.
CRC Offload: Offloads CRC computation and packet encapsulation to hardware.
Full TCP/IP stack offload (TOE) involves offloading the entire TCP/IP stack to hardware, significantly reducing CPU overhead and enhancing network processing performance. However, TOE NICs face several challenges in the Linux kernel:
Security Risks: Hardware implementations pose greater security risks compared to well-tested software TCP/IP stacks.
Hardware Constraints: TOE chips have limited resources compared to the ample CPU and memory available to software.
Complexity: TOE requires extensive changes to the network stack, potentially affecting QoS and packet filtering.
Customization: Vendor-specific TOE implementations increase complexity and security risks, with closed-source firmware limiting modifications.
Obsolescence: TOE NICs have a limited lifespan, with CPU performance quickly surpassing TOE capabilities and software stack iterations outpacing hardware protocol updates.
Due to these challenges, TOE has not been widely adopted.
2.2 Application Layer TCP/IP Stack Onload
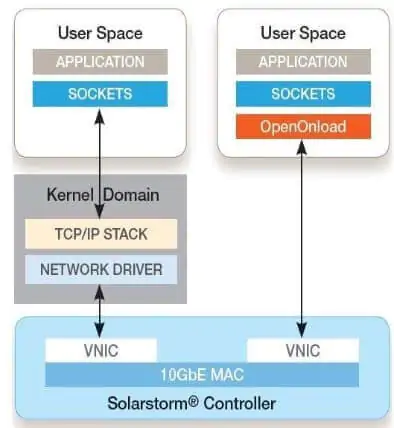
Onload is a network acceleration middleware developed by Solarflare, later acquired by Xilinx and subsequently by AMD. Onload enhances network performance by enabling IP-based TCP/UDP implementation directly in the user-mode application address space, allowing direct network data transmission and reception without OS involvement. Key features of Onload include:
Kernel Bypass: Avoids disruptive events like system calls, context switching, and interrupts, improving processor efficiency for application code execution.
Dynamic Linking: Onload dynamically links with applications using the standard Socket API at runtime, eliminating the need for application modifications.
Cost Reduction: Significantly reduces network costs by decreasing CPU overhead, improving latency and bandwidth, and enhancing application scalability.
Core Technologies: Onload utilizes hardware virtualization SR-IOV, kernel bypass, and application Socket API.
2.3 Optimizing Transport Protocols: From TCP to QUIC
QUIC (Quick UDP Internet Connections) is a new internet transport protocol that partially or fully replaces and optimizes layers 4, 5 (security), and 7. Unlike legacy protocols, QUIC is self-contained, allowing for innovation free from existing middleware constraints.
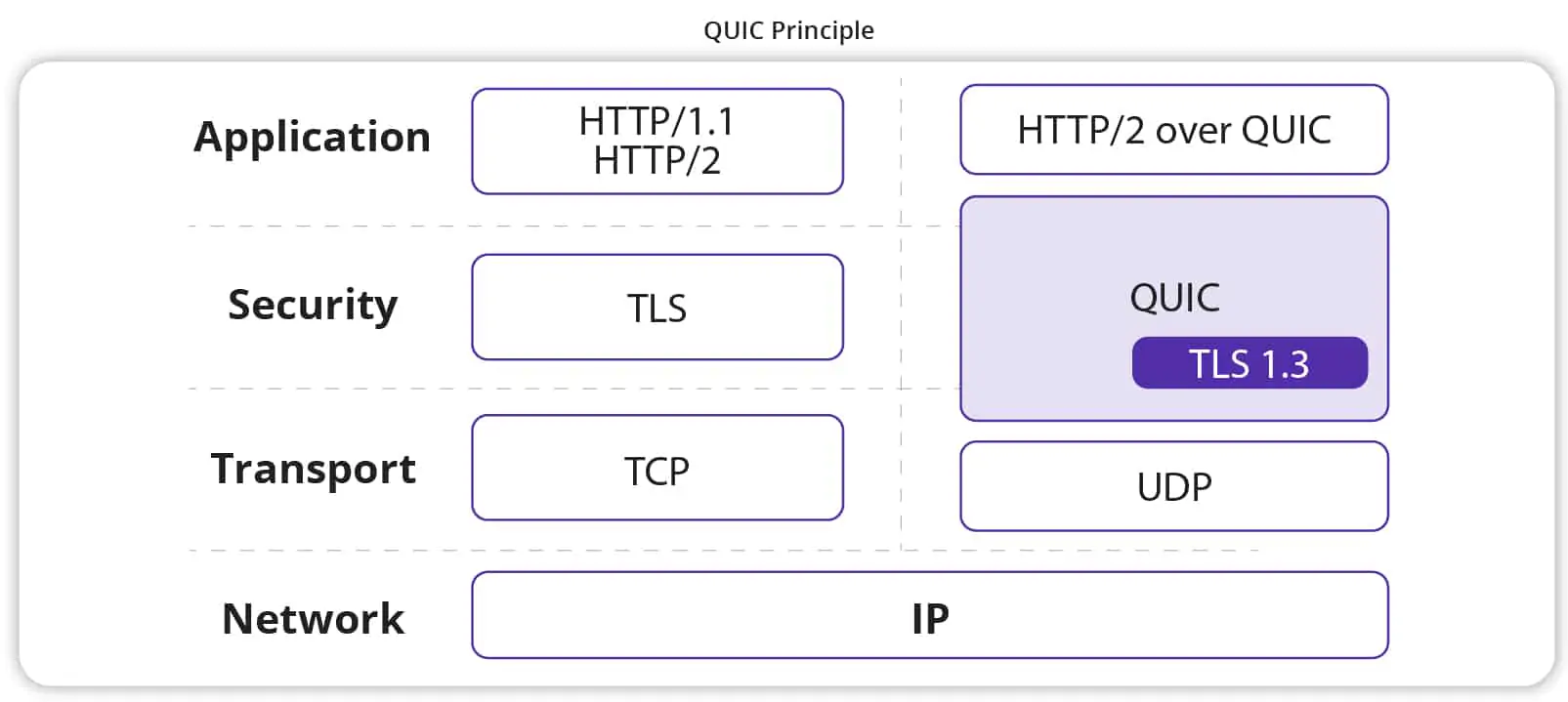
QUIC offers several advantages over TCP+TLS+HTTP2:
Connection Establishment Latency: Requires 0 RTT to send payloads before handshake, whereas TCP+TLS requires 1-3 RTTs.
Improved Congestion Control: Implements and optimizes TCP's slow start, congestion avoidance, fast retransmit, and fast recovery. QUIC can select different congestion control algorithms based on conditions, avoid TCP retransmission ambiguities, and allow precise RTT calculations.
Non-Blocking Multiplexing: Designed for multiplexing without head-of-line blocking, allowing non-impacted streams to progress.
Forward Error Correction (FEC): Recovers lost packets without waiting for retransmissions by supplementing a group of packets with an FEC packet.
Connection Migration: Identified by a 64-bit connection ID rather than a four-tuple, allowing the connection to remain valid even if the client's IP address or port changes.
3. Overview of High-Performance Network Protocols: InfiniBand (IB)
3.1 Introduction to IB Network Protocol
InfiniBand (IB) is a high-performance computing network communication standard known for its extremely high throughput and low latency. It is used for interconnections between computers and within computers, serving as a direct or switched interconnection between servers and storage systems. The design goals of IB include integrating computing, networking, and storage technologies to create a scalable, high-performance communication and I/O architecture.
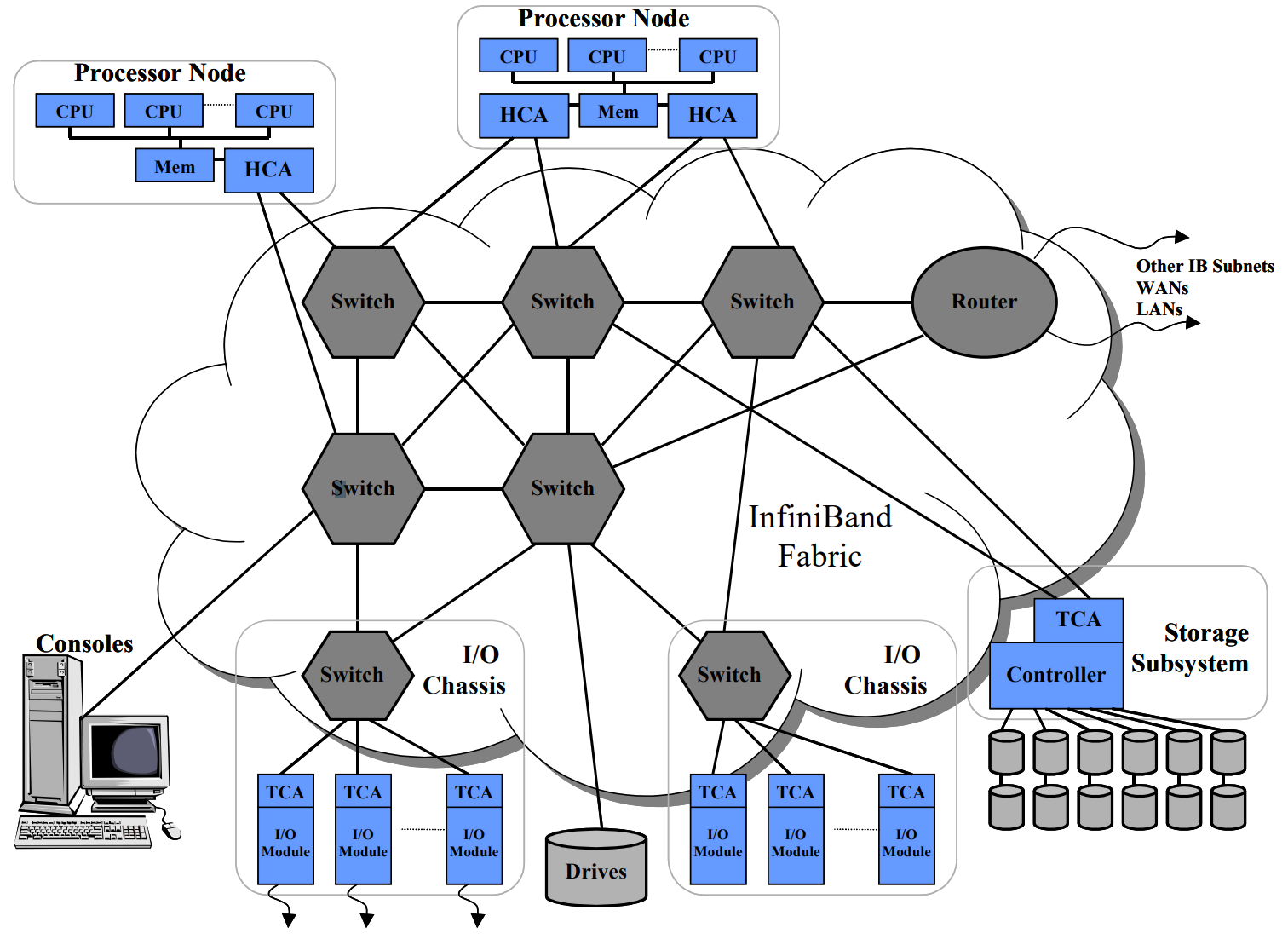
Key advantages of IB include:
High Performance: Approximately half of the TOP500 supercomputers use IB.
Low Latency: End-to-end IB latency is measured at 1µs.
High Efficiency: Native support for RDMA and other protocols enhances workload processing efficiency.
IB follows a five-layer network model: Physical, Link, Network, Transport, and Application layers. Unlike traditional networks where L1 & L2 are hardware-based and L3 & L4 are software-based, IB implements L1-L4 in hardware. The IB transport layer API connects HCA NICs and CPUs, with Verbs API as the application network interface for IB, similar to the Socket API for traditional TCP/IP networks. MPI, a method library for parallelization, can be based on OFA Verbs API or TCP/IP Socket.
3.2 Why is IB High-Performance?
Traditional network protocol stacks face several challenges, such as long paths through the system layer, unnecessary data copies, and limited optimization due to kernel involvement. IB overcomes these challenges with four key optimization techniques:
Optimized Protocol Stack: A simplified, lightweight, and decoupled system stack.
Accelerated Protocol Processing: Hardware acceleration of multiple protocol layers (L2-L4).
Reduced Intermediate Steps: Native support for RDMA kernel bypass.
Optimized Interface Interaction: Enhanced soft/hardware interaction mechanisms, including Send/Receive Queue Pairs and Work/Completion Queues.
3.3 InfiniBand vs. Ethernet

Comparisons between InfiniBand and Ethernet reveal distinct differences:
Design Goals: Ethernet focuses on compatibility and distribution across multiple systems, while IB aims to address data transmission bottlenecks in HPC scenarios.
Bandwidth: IB offers faster network speeds than Ethernet, primarily because it is used for server interconnects in HPC, while Ethernet targets end-device interconnects.
Latency: Ethernet switches handle more complex tasks, resulting in higher latency (>200ns), whereas IB switches perform simpler tasks with much lower latency (<100ns). The latency of an RDMA+IB network is around 600ns, compared to Ethernet+TCP/IP latency, which can reach 10µs.
Reliability: IB provides end-to-end flow control, minimizing latency jitter and avoiding congestion. Ethernet lacks scheduling-based flow control, which can lead to congestion and packet loss, causing significant performance fluctuations.
Networking Methods: Adding or removing nodes in an Ethernet network requires notifying all nodes, leading to broadcast storms as the node count increases. IB uses a subnet manager to configure Local IDs and uniformly calculate forwarding path information, allowing for the deployment of large Layer 2 networks with tens of thousands of servers.
4. RDMA High-Performance Networking
4.1 Overview of RDMA
Remote Direct Memory Access (RDMA) is a high-bandwidth, low-latency networking technology designed to reduce CPU consumption and overcome the limitations of traditional TCP/IP networks. RDMA enables direct data transfer between the memory of two nodes without involving the operating system, leveraging NIC hardware to handle the transmission. This direct memory access eliminates the need for additional data copying, with operations such as send/receive and read/write directly accessing application virtual memory.
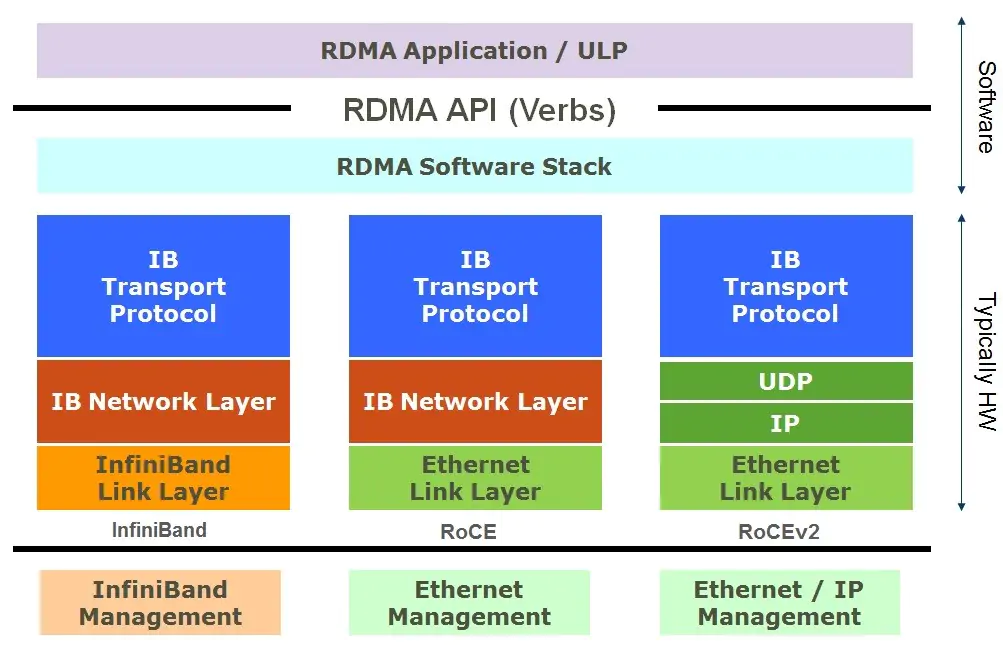
RDMA has several distinct features. It is natively integrated with InfiniBand (IB) and has implementations like RoCEv1, RoCEv2 builds on standard Ethernet, IP, and UDP, supporting standard L3 routers, making it a popular choice in data centers.
4.2 RDMA/RoCEv2 System Stack Layers
RoCEv2, a widely used RDMA technology in data centers, demonstrates the layered approach of RDMA systems. The stack layers include:
Ethernet Layer: The physical and data link layers of the five-layer network protocol.
Network Layer (IP): The network layer in the five-layer protocol.
Transport Layer (UDP): The transport layer, uses UDP instead of TCP.
IB Transport Layer: Manages packet distribution, segmentation, channel multiplexing, and transport services.
RDMA Data Engine Layer: Handles data transfer between memory queues and RDMA hardware, processing work/completion requests.
RDMA Interface Driver Layer: Manages RDMA hardware configuration, queue, and memory management, adding work requests to queues, and processing completion requests.
Verbs API Layer: Encapsulates interface drivers, managing connection states, memory, and queue access, submitting work to RDMA hardware, and retrieving work and events from the hardware.
ULP Layer: Provides RDMA verbs support for various software protocols, allowing seamless application migration to RDMA platforms.
Application Layer: Includes RDMA-native applications developed using the RDMA verbs API and existing applications leveraging RDMA through the OFED protocol stack.
4.3 RDMA Work Queues
RDMA utilizes a flexible software-hardware interface, allowing varied implementations across vendors unified by the queue mechanism. Interaction between software drivers and hardware devices follows a producer-consumer model, enabling asynchronous decoupling. The shared data structure for RDMA software and hardware is called the Work Queue.
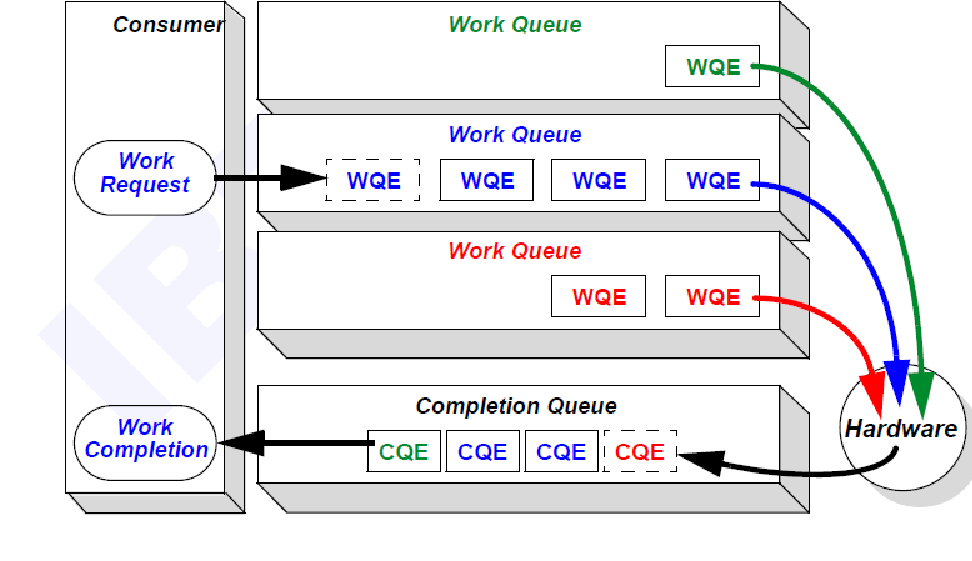
Drivers add work requests (Work Requests) to the Work Queue, forming Work Queue Entries (WQEs). RDMA hardware processes these WQEs, transferring them through memory and the RDMA network to the receiver's Work Queue. The receiver's hardware sends confirmation to the sender's hardware, generating Completion Queue Entries (CQEs) in the memory's Completion Queue.
Types of RDMA Queues include Send Queue, Receive Queue, Completion Queue, and Queue Pairs. Shared Receive Queue (SRQ) allows a Receive Queue to be shared among all associated Queue Pairs.
4.4 RDMA Verbs API
RDMA Verbs provide an abstraction for RDMA functionalities and actions accessible to applications. The Verbs API is the concrete implementation offering standard interfaces for application calls. In RoCEv2, Verbs operations are mainly categorized into:
Send/Receive: In a client/server model, the send and receive operations collaborate, with the receiver listening before the sender connects. The sender and receiver are unaware of each other’s virtual memory locations, requiring pre-registration of memory areas for direct memory operations.
Write/Read: Unlike the client/server model, the requestor initiates Write/Read operations, with the responder remaining passive. The requestor must obtain the responder's address and key in advance to access the responder's memory.
5. AWS SRD High-Performance Networking
5.1 Overview of AWS SRD and EFA
Scalable Reliable Datagram (SRD) is AWS's high-performance, low-latency network transport protocol, and Elastic Fabric Adapter (EFA) is a high-performance network interface for AWS EC2 instances. SRD leverages standard Ethernet to optimize transport protocols, inspired by InfiniBand’s reliable datagram but adapted for large-scale cloud workloads using AWS's multipath backbone network. EFA supports HPC applications using MPI and ML applications using NVIDIA’s NCCL, scaling to thousands of CPUs or GPUs. EFA exposes reliable unordered delivery capabilities, with packet reordering handled by libfabric.
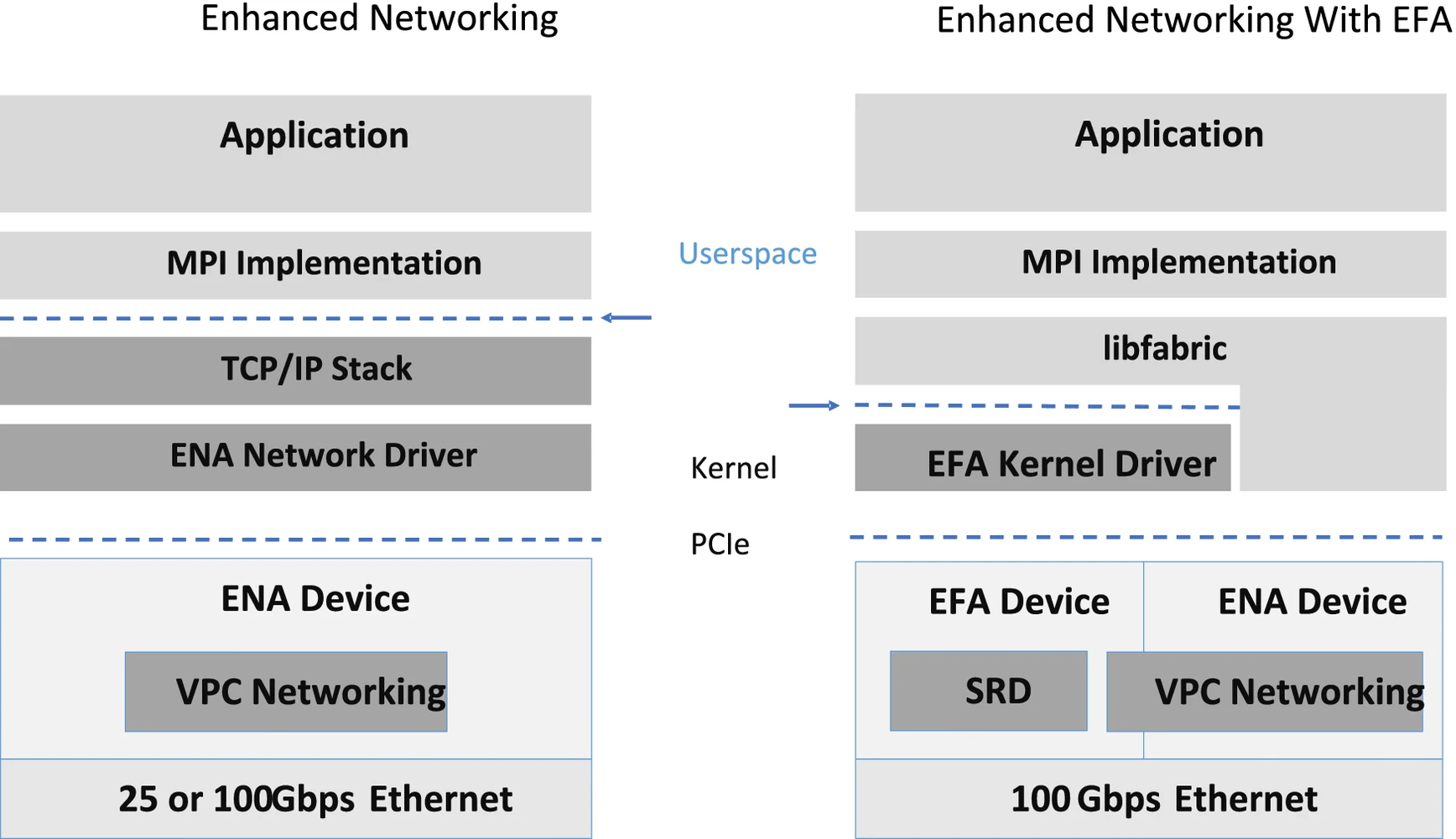
5.2 Why AWS Chose SRD Over TCP or RoCE
AWS finds TCP unsuitable for latency-sensitive workloads due to its high retransmission latency, often causing delays from 25 microseconds to 50 milliseconds or more. While InfiniBand provides high throughput and low latency for HPC, it lacks scalability due to issues with priority flow control (PFC) in RoCEv2, leading to head-of-line blocking, congestion spread, and potential deadlocks. SRD, optimized for large data centers, offers multipath load balancing, rapid recovery, sender-controlled ECMP, dedicated congestion control algorithms, and reliable but unordered delivery, implemented in the AWS Nitro card to minimize OS and hypervisor noise.
5.3 SRD Feature: Multipath Load Balancing
AWS SRD ensures optimal load balancing across multiple paths to minimize packet loss and congestion. SRD sprays packets across available paths, even within single application flows, to reduce hotspot occurrences and detect suboptimal paths. SRD avoids overloaded paths to ensure fair network sharing with traditional non-multipath traffic. If the original path becomes unavailable, SRD quickly reroutes retransmitted packets, enabling rapid recovery from link failures.
5.4 SRD Feature: Unordered Delivery
Multipath load balancing inherently causes packet reordering, but in-network reordering is costly and limited by NIC resources. SRD addresses this by passing potentially unordered packets directly to the host. Handling packet reordering in-network would require significant memory bandwidth and reordering buffer capacity, which are typically limited in NICs. Maintaining order in message-based semantics is feasible, as applications can manage unordered packets through the higher-level messaging layer. This approach avoids the need for large buffers and reduces average delay, preventing packet loss due to excessive delay and unnecessary retransmissions. While reordering packets is impractical in byte-stream protocols like TCP, it is manageable with message-based protocols, where SRD remains invisible, leaving message layer sorting to applications.
5.5 SRD Feature: Congestion Control
Incast congestion occurs when multiple flows converge on a single switch interface, exhausting buffer space and causing packet loss. While multipath spraying reduces the load on intermediate switches, it doesn't fully resolve incast congestion. SRD's congestion control aims to achieve fair bandwidth sharing with minimal in-flight data, preventing queue buildup and packet loss. Spray might worsen incast issues since packets from the same sender could arrive simultaneously via different paths, overwhelming the buffer. To mitigate this, SRD ensures all paths' aggregate queues are kept minimal, adjusting transmission rates based on rate estimates derived from acknowledgment timings. By maintaining minimal queue lengths and considering recent transmission rates and RTT variations, SRD optimizes bandwidth allocation and ensures efficient data transmission even under high load conditions.
6. Other High-Performance Networking Technologies
6.1 Microsoft Fungible TrueFabric
TrueFabric, based on standard UDP/IP Ethernet, is designed to enhance data center performance, scalability, reliability, and security. It supports direct server-to-Spine switch connections for small to medium deployments and Spine-Leaf topologies for larger scales. TrueFabric offers full cross-sectional bandwidth, low latency, low jitter, fairness in bandwidth allocation, congestion avoidance, fault tolerance, and software-defined security. It fully interoperates with standard Ethernet and TCP/IP, enabling scalable deployment from small clusters to tens of thousands of servers.
TrueFabric, an open-standard network technology, significantly improves data center performance, cost-efficiency, reliability, and security, supporting clusters ranging from a few servers to thousands of racks. As data centers expand horizontally, connecting all server nodes through reliable high-performance local area networks, TrueFabric addresses the inherent bottlenecks of TCP/IP.
LAN speeds exceed WAN speeds by several orders of magnitude, making TCP/IP a performance bottleneck. Despite attempts to offload TCP processing, clear delineation between CPU and offload engine tasks remains challenging. The rapid performance improvements in network interfaces and SSD devices, combined with the growing East-West traffic and advancements in I/O technologies and applications, place enormous pressure on network stacks. TrueFabric's features are implemented through the Fabric Control Protocol (FCP) over standard UDP/IP Ethernet.
TrueFabric supports various deployment scales:
- Small to Medium: Direct server-to-Spine switch connections.
- Large: Two-layer Spine and Leaf switch topology, with potential support for three or more layers for larger networks.
TrueFabric's network deployment includes four types of servers: CPU servers, AI/data analysis servers, SSD servers, and HDD servers, each with a Fungible DPU.
Key Features of TrueFabric/FCP:
- Scalability: Ranges from small deployments using 100GE interfaces to large-scale deployments using 200/400GE interfaces, supporting tens of thousands of servers.
- Full Cross-Section Bandwidth: Ensures end-to-end bandwidth for standard IP Ethernet packet sizes, supporting efficient exchange of short, low-latency messages.
- Low Latency and Jitter: Minimizes node-to-node latency with strict control over tail latency.
- Fairness: Allocates network bandwidth fairly among competing nodes at microsecond granularity.
- Congestion Avoidance: Built-in active congestion avoidance ensures packet loss due to congestion is rare and does not rely on core network switch features.
- Fault Tolerance: Features built-in packet loss detection and recovery, offering error recovery five orders of magnitude faster than traditional routing protocol-dependent methods.
- Software-Defined Security and Policies: Supports AES-based end-to-end encryption, allowing specific deployments to be configured as separate encrypted domains.
- Open Standards: FCP, based on Ethernet and standard IP, fully interoperates with standard TCP/IP over Ethernet.
Performance comparisons between TrueFabric and RoCEv2 under 10:1 Incast conditions show significant improvements in P99 tail latency and performance stability for TrueFabric.
6.2 Alibaba Cloud HPCC and eRDMA
Alibaba Cloud's High Precision Congestion Control (HPCC) utilizes In-Network Telemetry (INT) for precise link load information, enabling accurate traffic updates and rapid load adjustment to maintain high link utilization and low congestion. HPCC addresses the challenges of balancing low latency, high bandwidth utilization, and stability in large-scale RDMA networks. Classic RDMA congestion mechanisms like DCQCN and TIMELY have limitations such as slow convergence, unavoidable packet queuing, and complex parameter tuning.
HPCC allows senders to quickly adjust traffic to achieve high utilization or avoid congestion. Senders can maintain each link's input rate just below its capacity, ensuring high utilization. With rate calculations based on direct measurements from switches, HPCC only requires three independent parameters to balance fairness and efficiency. Compared to DCQCN and TIMELY, HPCC responds faster to available bandwidth and congestion, maintaining near-zero queues.
Elastic Remote Direct Memory Access (eRDMA) extends traditional RDMA benefits to Virtual Private Cloud (VPC) networks, providing high throughput, low latency, large-scale RDMA networking with dynamic device addition and compatibility with both HPC and TCP/IP applications.
Key Advantages of eRDMA:
- High Performance: Bypasses the kernel protocol stack, transferring data directly from user-space programs to the HCA, significantly reducing CPU load and latency. eRDMA retains the advantages of traditional RDMA NICs while extending RDMA technology to VPC networks.
- Scalable Deployment: Traditional RDMA requires lossless network conditions, making large-scale deployments costly and challenging. eRDMA, using self-developed congestion control algorithms, tolerates varying network conditions (latency, packet loss), maintaining good performance even in lossy environments.
- Elastic Expansion: Unlike traditional RDMA NICs that require dedicated hardware, eRDMA can dynamically add devices during ECS usage, supporting hot migration and flexible deployment.
- Shared VPC Network: eRDMA attaches to Elastic Network Interfaces (ENIs), fully reusing the network without altering business networking configurations, activating RDMA features seamlessly.
6.3 Emerging Ultra-Ethernet
The Ultra Ethernet Consortium (UEC), founded in July 2023, aims to surpass existing Ethernet capabilities, offering optimized high-performance, lossless transport layers for AI and HPC. UEC's open, interoperable, high-performance communication stack will address scalability, bandwidth density, multipath routing, rapid congestion response, and inter-stream dependency. UEC targets the development of open protocol standards and software to support large-scale AI and HPC networks with efficient, fair, and low-latency data transmission.
Artificial intelligence and high-performance computing bring new challenges to networking, such as the need for larger scale, higher bandwidth density, multipath capabilities, rapid congestion response, and execution of single data stream dependencies, with tail latency being a critical consideration. The UEC specifications aim to address these gaps, providing the necessary scale for these workloads.
Technical Objectives of UEC:
- Protocols and Signal Characteristics: Defines communication protocols, electrical and optical signal characteristics, and application interfaces/data structures for Ethernet.
- Link-Level and End-to-End Transport Protocols: Develop scalable or replaceable existing link and transport protocols.
- Congestion, Telemetry, and Signaling Mechanisms: Implements mechanisms suitable for AI, ML, and HPC environments.
- Support for Diverse Workloads: Provides structures for software, storage, management, and security.
- Open Protocol Standard: Designed to run on IP and Ethernet, fully interoperable with standard TCP/IP.
- Multipath and Packet Spray Transmission: Utilizes AI network capabilities to prevent congestion or head-of-line blocking, eliminating the need for centralized load balancing algorithms and routing controllers.
- Incast Management: Minimizes packet loss through incast management at the final link to the target host.
- Efficient Rate Control Algorithms: Allows rapid transmission ramp-up to line speed without affecting competing flows.
- Disordered Packet Delivery API: Enables selective message completion, maximizing network and application concurrency and minimizing message delay.
- Scalable Future Networks: Supports up to 1,000,000 endpoints.
- Optimal Network Utilization: Achieves line-rate performance on commercial hardware without specific congestion algorithm parameter tuning.
- High-Speed Ethernet: Aims to achieve line-speed performance for 800G, 1.6T, and future faster Ethernet on commercial hardware.
7. High-Performance Global Networks
With the widespread deployment of 5G infrastructure and increasing use of multimedia applications, autonomous vehicles, and VR/AR technologies, global networks face higher demands for throughput, real-time performance, and stability. Technologies like SD-RTN (Software Defined Real-time Network) from Agora leverage SDN architecture and intelligent routing to achieve global end-to-end latency control within 400ms, enhancing real-time communication across the globe.
8. Summary
8.1 Optimization Strategies
High-performance network optimization involves several key strategies to ensure robust and efficient data transmission. Upgrading network capacity, such as increasing bandwidth from 25Gbps to 100Gbps, is fundamental. Implementing lightweight protocol stacks tailored for short physical distances helps reduce latency, while hardware acceleration of network protocols and efficient software-hardware interaction (as exemplified by AWS EFA) further enhance performance. Techniques like multipath load balancing, unordered delivery, congestion control, and parallel processing are essential to achieving low latency, high reliability, and optimal network utilization.
8.2 System Layering in High-Performance Network Protocol Stacks
A high-performance network system is composed of multiple layers, each functioning as an independent module. Customizing and optimizing specific layers based on business needs, while ensuring collaboration across layers, is crucial for achieving peak performance. Continuous optimization of each layer, including interaction interfaces and the overall system, is necessary to meet evolving business requirements. This approach ensures a well-integrated and high-performing network infrastructure.
8.3 NADDOD Powers High-Performance Network Building
NADDOD is at the forefront of high-performance networking, leveraging its expertise in high-speed data transfer technologies like InfiniBand and RoCE. Its product range includes optical transceivers in various form factors, DACs, and AOCs, tailored to meet the demands of HPC, AI, and large-scale data centers. By providing these advanced networking solutions, NADDOD enables organizations to achieve outstanding performance and scalability.

NADDOD's commitment to excellence is evident in its state-of-the-art InfiniBand NDR solution, designed to revolutionize high-speed data transfer in HPC and AI applications. InfiniBand solutions offer ultra-low latency and high bandwidth, making them ideal for data-intensive tasks. The NDR optical transceivers provide several key advantages:
Firmware Compatibility: Extensive compatibility testing with multiple versions of NVIDIA firmware, as well as ensuring compatibility with the latest firmware versions from device manufacturers, guarantees that the modules maintain high performance and stability even after firmware updates.
Comprehensive Testing: Each transceiver undergoes a thorough inspection process and real-world testing on original equipment to ensure 100% compatibility and high product quality, guaranteeing seamless integration with other brands' optical modules and preventing issues with non-functional products.
Advanced Cooling Technology: NADDOD’s transceivers use cutting-edge cooling techniques to maintain optimal performance in high-density cluster environments, effectively preventing overheating and ensuring link stability.

Through continuous innovation and a dedication to meeting customer needs, NADDOD leads the way in high-performance networking advancements. Its solutions enhance data center efficiency and support the scalability and flexibility required for future growth. By focusing on cutting-edge technologies and maintaining rigorous standards, NADDOD ensures that its clients are equipped with the most reliable and high-performing network infrastructure available, driving the next generation of networking excellence.

 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1Next-Gen Data Centers: Embracing Liquid Cooling
- 2The Evolution of AI Capabilities and the Power of 100,000 H100 Clusters
- 3What is High-Performance Computing (HPC)?
- 4Introduction to Open-source SONiC: A Cost-Efficient and Flexible Choice for Data Center Switching
- 5OFC 2025 Recap: Key Innovations Driving Optical Networking Forward









