






























NVIDIA GB300 Deep Dive: Performance Breakthroughs vs GB200, Liquid Cooling Innovations, and Copper Interconnect Advancements.

NVIDIA unveiled its Blackwell architecture GPUs on March 19, 2024, most notably with the release of the B200, B100, and GB200 GPUs, alongside the GB200-NVL72 and GB200-SuperPod. We’ve already conducted an in-depth analysis of the GB200’s interconnect architecture, refering to NVIDIA GB200 Interconnect Architecture Analysis-NVLink, InfiniBand, and Future Trends.
This year, on March 19, at GTC 2025, NVIDIA announced the upgrade B300 and GB300 GPUs, and corresponding the DGX B300 and GB300-NVL72 systems. This article provides a comprehensive breakdown of the GB300’s latest advancements, offers a side-by-side comparison with the GB200, and highlights the key innovations and future trends driving this technological leap.
GB300 Full-Range Upgrade
1. Computing Power Boost
The GB300 delivers 1.5X the single-card 4-bit floating-point (FP4) performance of the GB200. This allows to faster computation speeds for complex AI workloads, significantly boosting productivity and saving datacenter’s substantial time costs.
2. Memory Capacity Upgrade
The GB300 features a major leap in memory capabilities with 12-layer stacked HBM3E memory, boosting capacity from 192GB in the GB200 to 288GB. This expanded memory allows AI models to process vastly larger datasets, enabling more efficient training and inferencing of massive deep learning models—accelerating AI advancements across industries.
3. Networking Capabilities Enhance
The GB300 upgrades its network adapters from ConnectX 7 to ConnectX 8, while its optical modules jump from 800G to 1.6T. This improvement dramatically boosts data transfer speeds and network bandwidth, enabling servers to handle large-scale distributed computing tasks with far greater efficiency. Reduced network latency and optimized data exchange further elevate overall system performance.
4. Power Consumption Increase
The GB300 operates at 1.4kW, marking a power increase over the GB200. While the GB200 and B200 have TDPs (Thermal Design Power) of 1.2kW and 1kW respectively, the GB300 and B300 push these figures to 1.4kW and 1.2kW. This power boost unlocks greater performance but also demands more advanced cooling solutions to manage the heightened thermal load.

GB300 NVL72 VS GB200 NVL72
As shown in the figure below, the key differences between the GB200 NVL72 and GB300 NVL72 include:
Dense FP4 Compute Boosted to 1.5X: The GB200’s dense FP4 compute is 720P (50% of its sparse FP4 compute at 1440P), while the GB300’s dense FP4 compute jumps to 1080P (75% of its sparse FP4 compute at 1440P).
INT8 Compute Nearly Eliminated: The GB200 delivers 360P INT8 sparse compute, whereas the GB300 drops to just 23P INT8 dense compute.
Other Compute Metrics: FP8, FP16/BF16, and TF32 performance remain identical. FP64 compute is also trimmed, though its limited use cases mitigate practical impact.
HBM Memory (Capacity 1.5x, Bandwidth remained at 8 TB/s per GPU):
- GB200: 72 GPUs × 192GB = 13.8TB total.
- GB300: 72 GPUs × 288GB = 20.7TB total.
LPDDR5X Memory: Minor changes.
- GB200: 36 × 480GB = 17.3TB total, 18.4TB/s bandwidth.
- GB300: 18TB total, 14.3TB/s bandwidth.
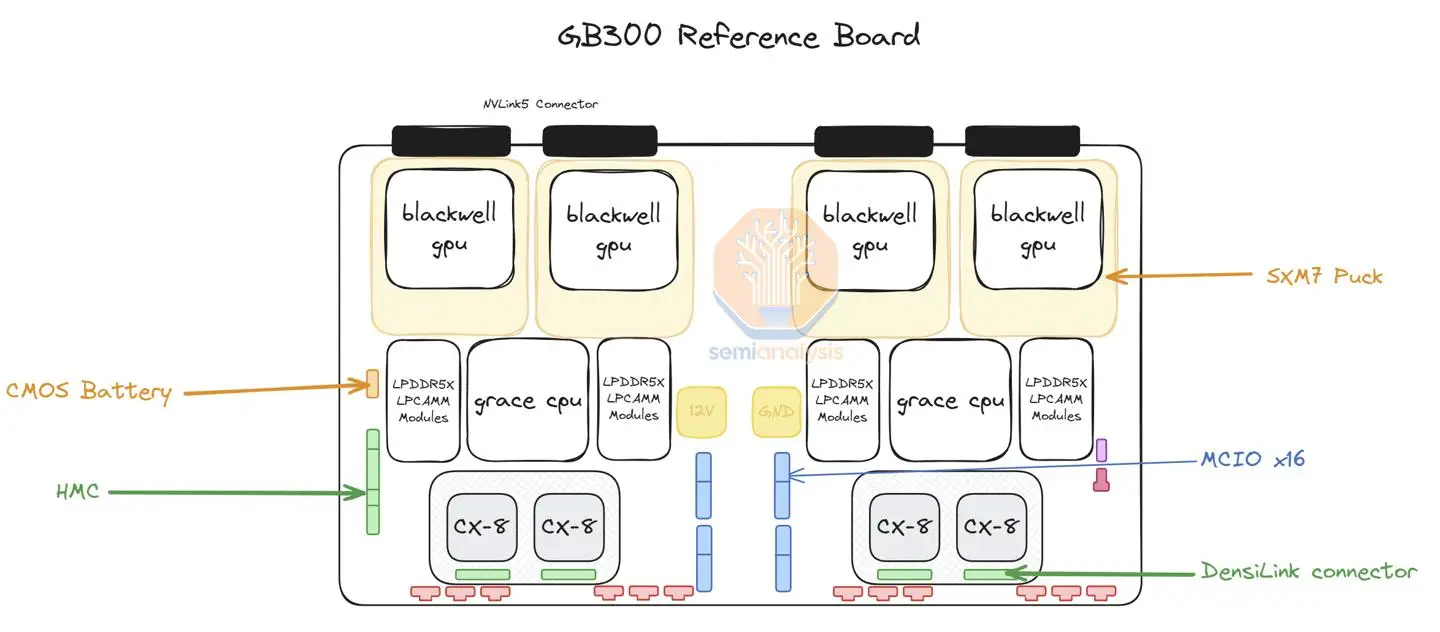
GB300 Liquid Cooling Revolution
The GB300’s formidable performance comes with a steep power demand. With a single-GPU TDP soaring to 1,400W and full-rack system power consumption reaching a staggering 125-130kW, NVIDIA has adopted a fully liquid-cooled thermal solution to tackle this challenge—significantly advancing liquid cooling technology.
While the GB300 retains the GB200’s design for components like manifolds, Cooling Distribution Units (CDUs), and cartridges, its core cooling module has been re-engineered to deliver breakthroughs in efficiency.
1. Individual Liquid Cold Plate Design
The GB300 abandons the GB200’s large-area cold plate approach, instead equipping each GPU chip with dedicated inlet/outlet liquid cold plates. This design significantly improves cooling efficiency while enabling more flexible hardware configurations. For example, in the NVL72 system, each compute tray houses 6 GPUs, with each GPU requiring two pairs of quick-connect couplings (one inlet, one outlet)—totaling 12 pairs per tray. Adding two couplings for manifold connections brings the total to 14 pairs per tray. Across the system’s 18 compute trays, this results in a staggering 252 pairs of couplings—more than double the GB200’s 108 pairs.
This dedicated cold plate design is a direct response to rising compute density demands. With the GB300’s more compact chip layout, traditional large cold plates can no longer meet thermal requirements. The shift to dedicated cold plates not only enhances cooling efficiency but also paves the way for future modular upgrades. However, this redesign significantly increases the number of quick-connect couplings and overall system complexity.
2. Miniaturized Couplings & Cost Efficiency
The GB300 adopts the new NVUQD03 quick-connect couplings, shrinking their size to one-third of previous models while slashing unit costs from $70-80 (GB200) to $40-50. This redesign addresses high-density layout requirements and significantly lowers the liquid cooling system’s total cost.
3. Thermal Efficiency & Reliability Challenges
While miniaturization could heighten leakage risks, the GB300 ensures stability through optimized sealing processes and rigorous accelerated testing—including insertion-extraction cycles and material durability validation. Although quick-connect couplings are still used between cold plates and manifolds, the cold plate side now features a recessed female port design, achieving a sleeker profile without compromising robustness.
Rack power demands have surpassed the limits of air cooling, making liquid cooling the inevitable path forward. According to Vertiv data:
- Below 20kW rack density: Air cooling remains viable.
- 20kW–75kW rack density: Hybrid air-liquid cooling with heat pipe rear-door heat exchangers becomes essential for thermal management.
- Above 75kW rack density: Only direct liquid cooling solutions can address the extreme thermal loads of high-power-density racks.
In the future, AI GPU rack power will far exceed 100kW, making liquid cooling indispensable.
GB300 High-Speed Copper Cable Connectivity
In the GB200 server, NVIDIA first introduced a copper cable backplane connectivity scheme, with a single NVL72 server using nearly 5,000 NVLink copper cables that span over 2 miles in total. The GB300 further optimizes the copper cable layout, with cable lengths expected to increase by 50% to meet higher performance and larger data transmission demands.
As a next-generation AI server, the GB300 comes standard with a CX8 network card that supports 1.6T optical modules (800G×2), placing extremely high demands on internal data transmission bandwidth. The short-distance interconnection scenario within a cabinet (<5 meters) necessitates low latency, low power consumption, and high-density cabling, making 1.6T copper cables (DAC or AEC) the optimal technological solution. With a single-channel rate of 224Gbps, these cables can satisfy the high bandwidth requirements achieved by aggregating multiple channels.
NADDOD has consistently focused on delivering high-performance optical networking solutions, prioritizing research into cutting-edge technologies and innovative products. Leveraging years of extensive experience in the AI industry and a precise understanding of market trends, we have pioneered the launch of 1.6T silicon photonics transceiver module. This breakthrough addresses the demand for ultra-high bandwidth and low power consumption in hyperscale data centers and high-performance computing environments. Utilizing NADDOD self-developed silicon photonics chip, which operates at 200G per channel, the module ensures rapid transmission of massive AI datasets, significantly reducing training and inference times for AI models. To explore the performance details of our 1.6T transceiver, please refer to: Focusing AI Frontiers: NADDOD Unveils 1.6T InfiniBand XDR Silicon Photonics Transceiver.
With advantages such as cost efficiency, low power consumption, and high reliability, Direct Attach Copper Cables (DAC) have become the preferred choice for high-speed connectivity in data centers. NADDOD’s DAC cables cover full-rate solutions from 100G to 800G, meeting the demands of bandwidth-intensive scenarios like hyperscale AI training and real-time inference. The cables fully support InfiniBand’s ultra-low latency architecture and RoCE-based lossless Ethernet, delivering zero packet loss and highly stable connectivity for GPU clusters and AI computing centers. Visit our website for more details on InfiniBand and RoCE networking solutions, or contact us at sales@naddod.com.

 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
