
































Customer Profile
Industry: AI Cloud
Objective: Modernize multi-building AI infrastructure to deliver ultra-low latency, near-zero downtime, and scalable cost efficiency for LLM training.
Core Focus: Balancing performance, stability, and total cost of ownership (TCO) in a 10,000+ NVIDIA H100 GPU network upgrade.
Background
In 2024, a global AI hyperscale cluster faced escalating demands to unify its distributed NVIDIA H100 GPU clusters across multiple data halls (inter-building links ≤2km). Previously reliant on short-reach DAC cables, the project aimed to consolidate fragmented networks into a unified InfiniBand NDR fabric optimized for trillion-parameter LLM training. Key requirements included:
- InfiniBand (NDR) Fabric: Spine-leaf topology for sub-microsecond GPU-to-GPU latency, critical for distributed training synchronization.
- Multi-Building Network Stability: Optical interconnects resilient to signal degradation over 2km, ensuring zero packet loss under TB-scale model training workloads.
- Future-Ready Scalability: Architectural flexibility to scale to 50,000+ GPUs without overhauling existing infrastructure, minimizing CAPEX/OPEX.
Core Concerns
Beyond the fundamental requirements, the hyperscaler faced key challenges in optimizing network efficiency, reliability, and cost-effectiveness:
- Simplifying Fiber Management Across Distributed Clusters
Rising cluster scale demanded extensive fiber paths across buildings. Legacy MPO-based solutions required more cabling per link (vs. 2-fiber alternatives), increasing deployment time, costs, and operational complexity. The challenge was to minimize cabling sprawl and operational overhead while maximizing existing infrastructure utilization.
- Ensuring Network Stability for AI Workloads
AI training is highly sensitive to network reliability—80% of training interruptions stemmed from network instability, with 95% of failures linked to optical interconnect issues. High bit error rates (BER) from unstable optical links led to retransmissions, training rollbacks, and increased latency, directly degrading model accuracy and project timelines.
- Maintaining Signal Integrity Over Long-Distance Links
With clusters spanning multiple buildings, interconnects required solutions for links ranging from 500m to 2km. Longer distances introduced cumulative signal attenuation, shrinking the optical power budget and increasing transmission errors. The customer needed a high-performance, long-reach solution to ensure error-free transmission at scale.
- Ensuring Seamless Compatibility with NVIDIA’s InfiniBand NDR Ecosystem
As a third-party optics adopter, the AI cluster needed assurance that modules and cables would match NVIDIA’s performance standards while remaining fully compatible with latest NVIDIA NDR hardware (e.g., Quantum-2 switches) and firmware updates. Compatibility gaps—such as outdated firmware lagging behind NVIDIA’s NDR releases—risked cluster-wide training halts.
- Optimizing Cost Efficiency Without Compromising Performance
Achieving ultra-low latency and high bandwidth without excessive CAPEX/OPEX was critical. The hyperscaler sought a connectivity solution that balanced cutting-edge performance with a cost-effective deployment model, particularly as optical modules represent a significant portion of network costs in fully utilized clusters—often exceeding the cost of switches themselves in high-density deployments.
NADDOD’s Solution for 10K H100 LLM Training Cluster
Collaborating with the cluster’s network architects, data center engineers, and AI infrastructure leads, NADDOD proposed a hybrid 800G 2xFR4/FR8 optical module + 800G DAC architecture tailored to address their core challenges.
To optimize performance, stability, and cost efficiency across the hyperscaler’s distributed H100 cluster, NADDOD recommended a dual-strategy approach:
- Leaf-to-Server: 800G DAC cables for short-reach (≤3m) connections within racks.
- Leaf-to-Spine: 800G 2xFR4 single-mode optical modules for long-reach (≤2km) inter-building links.
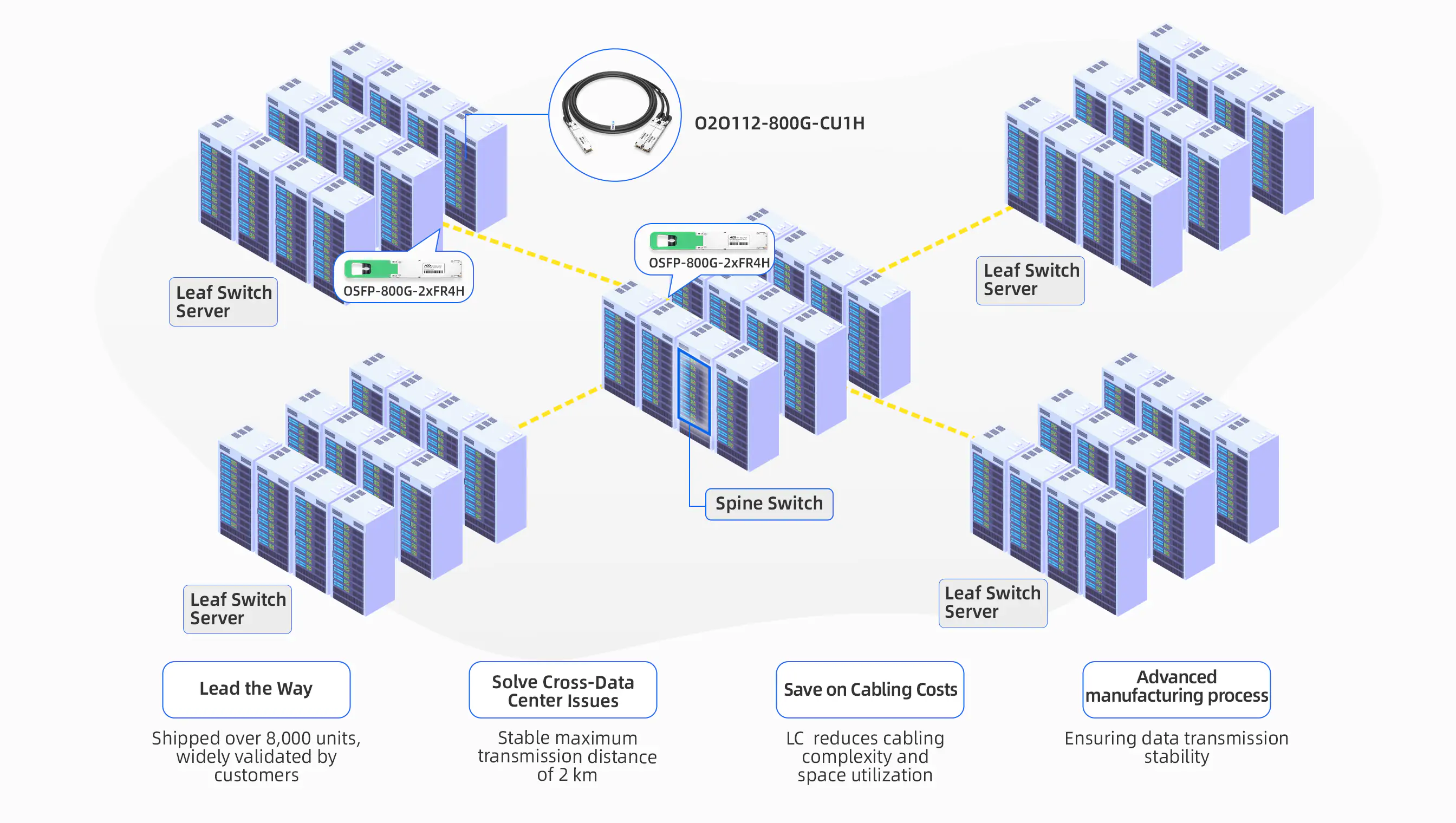
Hybrid 800G DAC + 2xFR4 deployment in a 2-layer leaf-spine architecture
Technical Advantages
Stability Across Short- and Long-Reach Links
NADDOD’s hybrid solution ensures robust performance across varying distances.
For short-reach rack-level connections, 800G DAC cables deliver ultra-low latency and error-free transmission between servers and leaf switches, leveraging the inherent stability of electrical signaling.
For long-reach inter-building links up to 2km, the 800G 2xFR4 optical modules—launched in October 2023 as an industry-first solution—combine EML lasers, nano-scale optical alignment, and optimized PCB layouts to minimize signal loss and crosstalk. Validated in NVIDIA NDR environments, these modules achieve a pre-FEC BER of 1E-8 to 1E-10 using Broadcom DSPs, with near-zero packet loss post-correction via RS-FEC (544,514) and LL-FEC (272,257+1), ensuring uninterrupted distributed training.

Seamless NVIDIA NDR Compatibility
NADDOD’s 800G 2xFR4 modules undergo rigorous compatibility testing with NVIDIA Quantum-2 InfiniBand NDR switches and NDR NICs across firmware versions, guaranteeing seamless interoperability during upgrades. This eliminates risks of cluster-wide training halts caused by firmware mismatches, providing plug-and-play reliability for hyperscale AI workloads.
Simplified Fiber Management & Cost Savings
By deploying 800G DAC cables for rack-local connections, the hyperscaler substantially reduced deployment costs compared to optical alternatives. For cross-building links, the 2xFR4 modules’ 2-fiber design (vs. traditional MPO-based solutions requiring multiple fibers) simplifies fiber management while minimizing resource bottlenecks. The LC connector design further streamlines high-density deployments, optimizing rack space utilization and reducing operational overhead—particularly critical in regions with elevated labor costs.
R&D Leadership in Scalable Optics
NADDOD’s patented thermal compensation technology stabilizes DWDM wavelengths (±0.1nm) across extreme temperatures, eliminating performance drift in long-haul transmissions. As the first vendor to mass-produce 800G FR8 modules, NADDOD ensures supply chain resilience and consistent quality for hyperscale deployments, future-proofing the cluster for seamless expansion.
Key Outcomes
Enhanced Training Efficiency
The ultra-low BER and near-zero packet loss of the 800G 2xFR4 modules ensured uninterrupted distributed training, reducing retransmissions and synchronization delays. LLM training jobs achieved accelerated convergence rates, with model accuracy improvements observed across trillion-parameterworkloads.
Operational Stability at Scale
- The solution maintained 99.9% cluster uptime over six months, with fewer than one monthly training interruption—critical for hyperscalers running round-the-clock AI workloads.
- Continuous signal integrity over 2km inter-building links eliminated performance degradation risks in multi-rack environments.
Cost-Effective Scalability
- The hybrid DAC + 2xFR4 architecture minimized fiber sprawl and labor-intensive deployments, aligning with the hyperscaler’s long-term TCO goals.
- NADDOD’s 24/7 global support and proactive firmware compatibility management reduced operational overhead, freeing the customer’s team to focus on AI innovation.
About NADDOD
NADDOD is a leading provider of high-speed optical connectivity solutions for AI, HPC, and hyperscale data centers. With three state-of-the-art manufacturing facilities and rigorous testing environments, we deliver:
- Cutting-Edge Products: InfiniBand and RoCE modules & cables (100G to 1.6T), 51.2T/25.6T switches, and immersion cooling-ready optics.
- Proven Expertise: Deployed in top-tier supercomputing centers and AI clusters worldwide, our solutions ensure cross-batch consistency, rapid delivery, and unmatched performance-per-watt.
Contact NADDOD to explore tailored InfiniBand and RoCE networking solutions for your AI clusters.

 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1Introduction to NVIDIA Dynamo Distributed LLM Inference Framework
- 2Blackwell Ultra - Powering the AI Reasoning Revolution
- 3NVIDIA’s Silicon Photonics CPO: The Beginning of a Transformative Journey in AI
- 4Introduction to Open-source SONiC: A Cost-Efficient and Flexible Choice for Data Center Switching
- 5OFC 2025 Recap: Key Innovations Driving Optical Networking Forward




