
































In AI and deep learning, GPU performance is key to accelerating model training and improving inference efficiency. NVIDIA’s H100, A100, A6000, and L40S GPUs, built on the company’s latest architectures, each play unique roles in this space. This article offers a detailed comparison of these GPUs, highlighting which models are best suited for large-scale training versus inference tasks. We’ll also look at real-world applications, showcasing how top companies leverage these GPUs to advance their AI projects.
What’s Best for Training and Inference?
To determine the ideal NVIDIA GPU for specific tasks, let’s compare the H100, A100, A6000, and L40S, focusing on their suitability for model training versus inference.
The table below summarizes key specs—architecture, FP16/FP32 performance, Tensor Core capabilities, memory size, memory type, and bandwidth—allowing easy comparison for different use cases.
|
GPU Model |
Architecture |
FP16 Performance |
FP32 Performance |
Memory |
Memory Type |
Bandwidth |
|
H100 |
Hopper |
1,671 TFLOPS |
60 TFLOPS |
80 GB |
HBM3 |
3.9 TB/s |
|
A100 |
Ampere |
312 TFLOPS |
19.5 TFLOPS |
40 GB / 80 GB |
HBM2 |
2,039 GB/s |
|
A6000 |
Ampere |
77.4 TFLOPS |
38.7 TFLOPS |
48 GB |
GDDR6 |
768 GB/s |
|
L40S |
Ada Lovelace |
731 TFLOPS |
91.6 TFLOPS |
48 GB |
GDDR6 |
864 GB/s |
Generally, newer architectures bring better performance. From oldest to newest, these are:
- Ampere (2020)- Found in the A100 and A6000, Ampere brought significant advancements in AI processing.
- Ada Lovelace (2022)- Powering the L40S, known for its superior FP32 and Tensor Core performance.
- Hopper (2022)- The backbone of the H100, delivering extreme computational power for the latest AI models.
Each GPU has unique strengths for tasks like large language model (LLM) training and high-concurrency inference. Here, we analyze their advantages and use cases to clarify the best options for different AI applications.
NVIDIA H100
NVIDIA H100 Applications
The NVIDIA H100 is designed for both AI model training and inference tasks, making it one of the most versatile GPUs available.
AI Model Training: As NVIDIA’s most advanced GPU, the H100 is purpose-built for large-scale AI model training. It offers immense compute power, substantial memory, and high bandwidth, which are essential for processing massive datasets required by large language models (LLMs) like GPT and BERT, capitalizing on the H100’s Tensor Core capabilities for faster computation. For example, xAI’s Colossus supercomputer leverages 10,000 H100 GPUs to accelerate training for its Grok models
Inference: While primarily optimized for training, the H100 is also highly effective in inference tasks, particularly with large models. Due to its power consumption and cost, however, it’s generally used for inference only when high concurrency or real-time performance is necessar
NVIDIA H100 Use Cases
Inflection AI
Supported by Microsoft and NVIDIA, Inflection AI is building a large-scale supercomputer cluster with 22,000 H100 GPUs. This powerful setup is aimed at advancing its AI chatbot, Pi, showcasing the H100’s capacity to handle demanding AI applications and high-performance requirements.
Meta
Meta plans to acquire 350,000 H100 GPUs by the end of 2024 as part of its investment in open-source AGI research and augmented reality (AR) infrastructure. This substantial commitment underscores Meta’s goal of enhancing its advanced AI capabilities and expanding its technology base for future AI and AR initiatives.
xAI Colossus
Elon Musk’s xAI Colossus supercomputer currently employs 100,000 liquid-cooled H100 GPUs to train the Grok family of LLMs, making it the world’s largest AI-focused supercomputer. With plans to double to 200,000 GPUs (including an anticipated addition of H200 GPUs), xAI Colossus demonstrates the H100’s role in driving next-generation AI research and high-scale deployment.
NVIDIA A100
NVIDIA A100 Applications
The A100 is a key GPU for AI training in data centers, particularly known for its strong performance in mixed-precision training. With high memory and bandwidth, it excels at processing large models and handling high-volume training tasks.
For inference, the A100’s powerful compute capabilities and large memory make it well-suited for complex neural networks and high-scale concurrent inference workloads.
NVIDIA A100 Use Cases
Microsoft Azure
Microsoft Azure has integrated A100 GPUs to enhance high-performance computing and AI scalability within its cloud services. This setup supports applications ranging from natural language processing to complex data analytics.
NVIDIA Selene Supercomputer
The NVIDIA Selene supercomputer, a DGX SuperPOD system, uses A100 GPUs to lead in AI research and high-performance computing (HPC). Notably, Selene ranks fifth on the Top500 list of fastest industrial supercomputers, setting records in scientific simulations and AI model training.
NVIDIA A6000
NVIDIA A6000 Applications
The A6000 is an ideal choice for workstation environments, especially when large memory is needed. Although it lacks the extreme compute power of the A100 and H100, it’s sufficient for training mid-sized models. Its high memory capacity also allows it to handle larger model training tasks.
For inference, the A6000 provides balanced performance, making it suitable for handling larger input data and high-concurrency tasks.
NVIDIA A6000 Use Cases
Las Vegas Sphere
The Las Vegas Sphere uses 150 NVIDIA A6000 GPUs to process and render animations displayed on its enormous dome screen, highlighting the A6000’s capability in high-resolution rendering and complex visual effects.
NVIDIA L40S
NVIDIA L40S Applications
The L40S is optimized for high-performance workstations, offering ample memory and compute power for mid-to-large model training. It excels when combining graphics processing with AI training, making it ideal for industries requiring both capabilities.
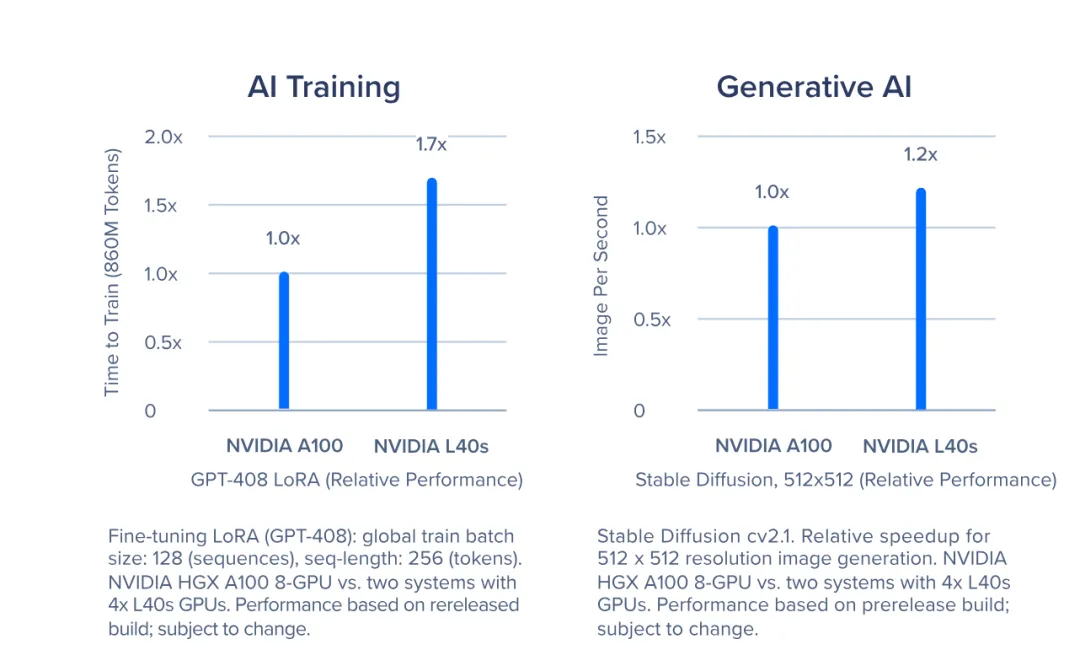
For inference, the L40S performs exceptionally well in workstation environments, particularly in complex inference tasks. Although the L40S is more affordable than the A100, it outperforms it by 1.2x in generative AI tasks, such as stable diffusion, due to its Ada Lovelace Tensor Cores and FP8 precision.
NVIDIA L40S Use Cases
Animation Studios
Animation studios rely on the L40S for 3D rendering and complex visual effects, benefiting from its ability to process high-resolution graphics and large datasets, making it a preferred choice in media and gaming.
Healthcare and Life Sciences
In healthcare, the L40S is employed for genomic analysis and medical imaging. Its data-processing power accelerates genetics research and enhances diagnostic accuracy through improved imaging capabilities.
Conclusion
Recommended GPUs for Model Training
For training large models like GPT-3 and GPT-4, the H100 and A100 stand out due to their exceptional compute power, memory, and bandwidth. The H100 offers superior performance, but the A100 remains a reliable choice in large-scale AI training. In workstation environments, the A6000 is ideal for mid-sized models, while the L40S provides balanced performance with strong FP32 and Tensor Core capabilities, though it doesn’t match the power of the H100 and A100.
Recommended GPUs for Inference
The A6000 and L40S are well-suited for inference, with ample memory and processing power for large-model inference tasks. The A100 and H100 also perform well in high-concurrency or real-time inference but may be overpowered for regular inference tasks due to their cost.
For multi-GPU setups in large-model training, NVIDIA’s NVLink is essential, though it’s available only on data center-grade GPUs. Without NVLink, the L40S is more suitable for inference or single-GPU training.
These recommendations are based on performance metrics and real-world use cases, but data centers and HPC environments should consider cost when making final choices. For high-performance AI clusters and supercomputers, NADDOD provides essential optical interconnect solutions, including InfiniBand and RoCE networking, immersion liquid cooling, and data center interconnect (DCI) technology. These solutions optimize AI infrastructure, enhancing model training and inference for business and research applications alike.

 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1Meta Trains Llama 4 on a 100,000+ H100 GPU Supercluster
- 2Introduction to NVIDIA DGX H100/H200 System
- 3Inside xAI Colossus, the 100,000-GPU Supercluster Powered by NVIDIA Spectrum-X
- 4Introduction to Open-source SONiC: A Cost-Efficient and Flexible Choice for Data Center Switching
- 5OFC 2025 Recap: Key Innovations Driving Optical Networking Forward


