
































With the exponential growth in AI, ML, and LLM, the surge in data traffic is pushing traditional network architectures to their limits, they need high bandwidth, high throughput, especially in large-scale AI training and real-time intelligent applications. High-performance GPUs are often deployed in large AI clusters to handle multiple complex model training tasks simultaneously, increasing traffic complexity and dynamic load on the network. This necessitates flexible and scalable network architectures to handle evolving traffic demands and ensure balanced load distribution.
To meet these requirements, NADDOD introduces the N9500 series 51.2T Ethernet/RoCE-based AI data center switches. These switches leverage high-speed 400G and 800G network technologies to significantly reduce latency and enhance data transmission efficiency. Designed for AI model training, large-scale parallel computing, and HPC, they are optimized to support AI-driven business growth. Additionally, the N9500 series is compatible with several NOS options, including Open Network Linux (ONL) — the open-source OCP reference NOS — and comes preloaded with SONiC OS.
NADDOD N9500-64OC: 64-Port 800G OSFP Ethernet AI Switch
The NADDOD N9500-64OC is a next-generation, high-performance, high-density box switch designed for AI, big data, HPC, and distributed storage applications. It provides up to 64 800G OSFP ports and leverages network flow control technologies such as PFC/ECN and MMU optimization to build a lossless, low-latency RDMA-based network, meeting the networking needs of AI, machine learning, HPC, and distributed storage scenarios.

NADDOD N9500-128QC: 128-Port 400G QSFP112 Ethernet AI Switch
The NADDOD N9500-128QC is engineered with advanced hardware architecture, featuring the Broadcom Tomahawk 5 (BCM78900) chipset, and provides 128 400GE ports with line-rate forwarding, redundant hot-swappable power supplies, and fans. Typical deployments support up to 8K 400G ports in Layer 2 networking. The switch also offers one-click RoCE configuration for simplified RDMA network deployment.

Core Features of NADDOD N9500 Series 51.2T Ethernet AI Switches
Large Scale Networking
AI training requires large-scale GPU clusters and distributed parallel computing. NADDOD's N9500 series, based on a multi-rail interconnect architecture, supports flexible expansion with Broadcom Tomahawk 5 chip-based switches (64-port 800G OSFP / 128-port 400G QSFP112).
- Supports typical clusters of up to 4,096 GPU servers (32,768 CX7 NICs) with 512 Leaf, 512 Spine, and 256 Core Spine switches.
- Each POD contains 64 GPU servers and up to 64 PODs, with 8 ToR switches per POD.
- 1:1 uplink-to-downlink traffic convergence ratio between ToR and Leaf layers, and Leaf and Spine layers.
- Inter-switch connections use NADDOD 800G OSFP or 400G QSFP112 DAC cables, optimizing cost and stability while reducing overall cluster power consumption.
- Switch-to-NIC connections use 800G OSFP 2xSR4 and 400G QSFP112 SR4 modules, offering flexible connectivity solutions.

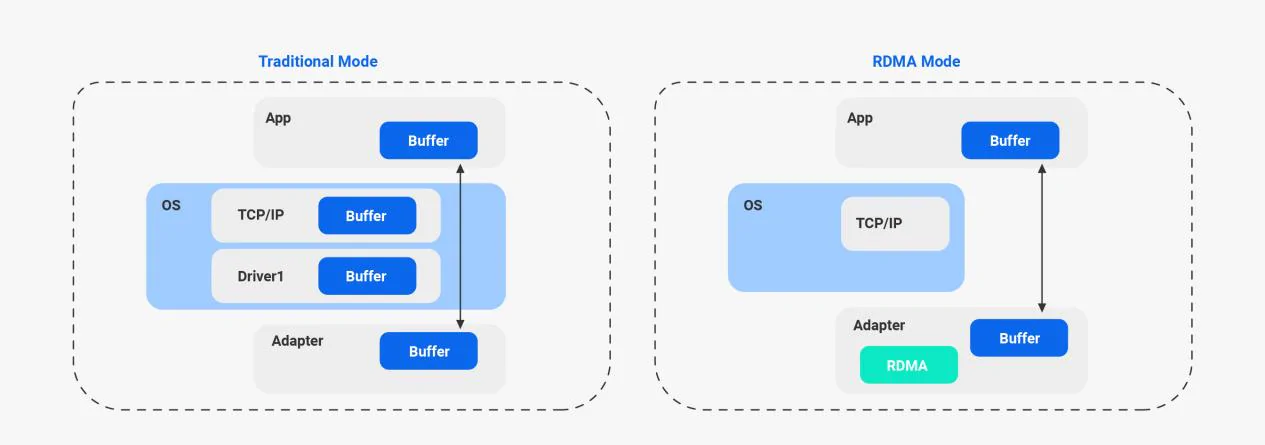
RoCE Lossless Technology
RoCE (RDMA over Converged Ethernet) is an RDMA technology based on the Ethernet protocol, available in two versions: RoCEv1 and RoCEv2. RoCEv2 offers enhanced features and performance, comparable to InfiniBand in dynamic latency, which is crucial for AI applications. Its standardized, open, and cost-effective nature makes it ideal for high-bandwidth, low-latency scenarios like HPC, distributed storage, and AI. NADDOD N9500 series switches support one-click RoCE configuration, enabling efficient and lossless RDMA communication over Ethernet with low-latency transmission for AI networks.
SONiC OS Support
All NADDOD N9500 Series 51.2T Ethernet switches are preloaded with SONiC (Software for Open Networking in the Cloud). SONiC is built on a modular, containerized architecture, where each network service runs in its own Docker container. This design supports hardware-software disaggregation, giving data center operators the freedom to run SONiC on a variety of hardware platforms.
Key Benefits of SONiC OS on NADDOD 51.2T switches include:
- Open and vendor-neutral architecture: SONiC runs on a wide range of switching hardware, enabling deployment flexibility across multi-vendor environments.
- Containerized service model: Core networking services (e.g., BGP, LLDP, SNMP) are implemented as independent Docker containers, enhancing fault isolation, simplifying updates, and enabling seamless restarts without disrupting forwarding.
- Advanced operational features: Built-in support for Zero Touch Provisioning (ZTP), warm restart, Critical Resource Monitoring (CRM), and detailed interface diagnostics.
- Automation and scalability: SONiC supports automation through Ansible modules, RESTful APIs, and streaming telemetry - making it ideal for managing large-scale, AI-driven data center networks.
Check how to configure SONiC OS on NADDOD switches →
Tip: NADDOD also offers ONIE-compliant bare-metal switches without a preloaded NOS, giving operators the flexibility to install and run a network operating system of their choice.
Cognitive Routing
Cognitive routing is a dynamic routing technology based on AI and machine learning, designed to optimize data transmission paths through self-learning and real-time decision-making. Unlike traditional routing protocols, cognitive routing adapts to changes in network conditions, traffic patterns, link status, and user needs, adjusting routing strategies in real-time for improved network performance and smarter traffic management.
- Efficient Network Resource Utilization: Real-time monitoring and learning improve bandwidth usage, reduce congestion, and minimize resource waste.
- Adaptive Capability: Quickly adjusts to changes in complex, dynamic network environments, ensuring service quality and stability.
- Intelligent Decision-Making: Uses AI algorithms for more complex and precise routing decisions, enhancing network responsiveness and overall performance.
Final Thoughts
Built on the industry-leading Broadcom Tomahawk 5 (51.2T) ASIC and powered by the open-source SONiC operating system, the NADDOD N9500 Series delivers ultra-high-density 400G/800G switching with advanced networking capabilities and tightly integrated hardware-software optimization.
Key benefits include high performance, operational efficiency, scalable utilization, and cost-effectiveness—with RoCE-based networks delivering up to 50% cost savings compared to InfiniBand at similar scales. Combined with compatible optical transceivers and cables, the N9500 Series offers a comprehensive intelligent networking solution, providing a stable, high-throughput foundation for modern AI and HPC workloads.
In AI data center environments, the stability and performance of optical interconnects—including transceivers and high-speed fiber cabling—are equally critical to ensuring consistent network reliability and efficiency. NADDOD brings deep expertise in high-speed optical connectivity, offering a full range of 200G/400G/800G/1600G transceivers and DAC/AOC cables. Our leadership in optical design ensures high compatibility, low power consumption, and exceptional performance under demanding workloads.
To support end-to-end deployment, NADDOD provides expert consultation and after-sales support for selecting matched optical modules and cabling. Every RoCE switch and optical component undergoes rigorous compatibility and stability testing to ensure seamless interoperability, maximize link performance, and maintain low latency across large-scale fabrics.

 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1Three Core Broadcom Optical Interconnect Technologies
- 2A Comprehensive Guide to 800G Optical Transceivers
- 3Silicon Photonics for AI - Balancing Cost, Power, and Reliability
- 4Introduction to Open-source SONiC: A Cost-Efficient and Flexible Choice for Data Center Switching
- 5OFC 2025 Recap: Key Innovations Driving Optical Networking Forward


