
































Since the release of GPT-4, some argue that AI capabilities have stagnated. This perception largely stems from the fact that no significant increases in computational power dedicated to individual models have been realized. Each newly released model has roughly matched GPT-4's training compute level, around 2e25 FLOP, due to the similar levels of computational resources allocated. Models like Google's Gemini Ultra, NVIDIA's Nemotron 340B, and Meta's LLAMA 3 405B, despite having comparable or higher FLOP allocations than GPT-4, failed to unlock new capabilities due to their inferior architectures.
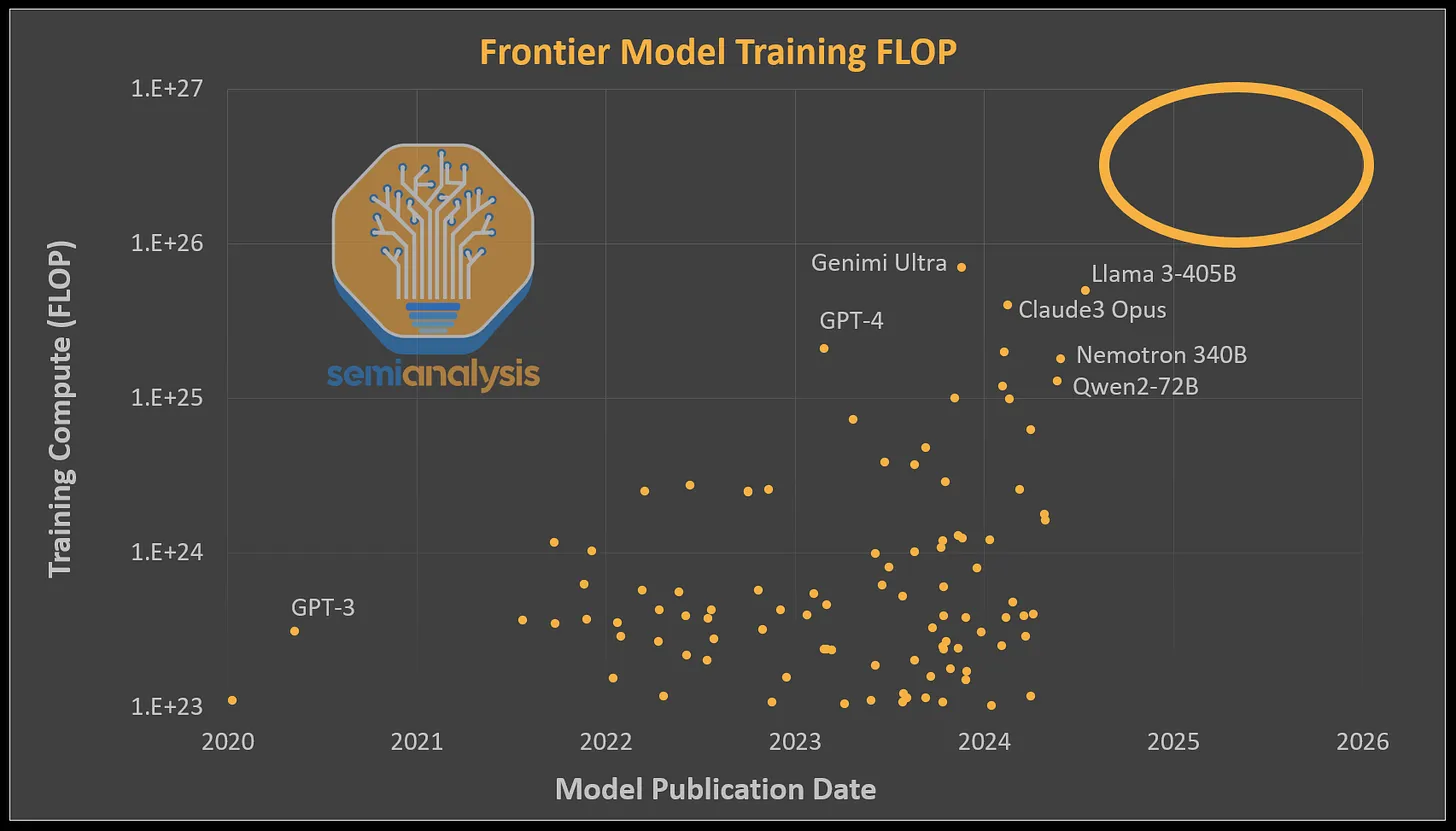
OpenAI has obtained more computational resources but has primarily focused on producing smaller, over-trained, and cheaper inference models, such as GPT-4 Turbo and GPT-4o. OpenAI has only recently commenced training the next tier of models.
The next step in AI's evolution is training a multi-modal transformer with trillions of parameters using vast amounts of video, image, audio, and text data. Although no one has achieved this yet, significant efforts are underway.
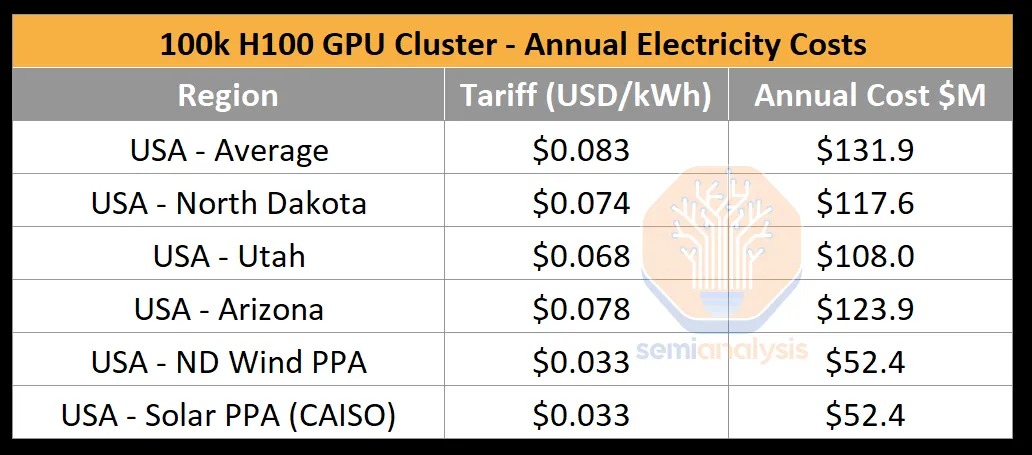
Several major AI labs, including OpenAI/Microsoft, xAI, and Meta, are racing to build GPU clusters exceeding 100,000 GPUs. The capital expenditure for these training clusters exceeds $4 billion just for servers. However, these clusters also face significant constraints due to data center capacity and power limitations. GPUs generally need to be colocated to enable high-speed chip-to-chip networking. A 100,000 GPU cluster would require over 150MW of data center capacity, consuming 1.59 TWh annually, costing approximately $123.9 million at a standard rate of $0.078 per kWh.
Today, we delve into the intricacies of large AI training clusters and their surrounding infrastructure. Building these clusters is far more complex than merely investing money. Achieving high utilization is challenging due to the high failure rates of various components, especially networking. We will explore power challenges, reliability, checkpointing, networking topology options, parallel schemes, rack layouts, and the overall bill of materials.
NVIDIA's InfiniBand has limitations, prompting some companies to opt for Spectrum-X Ethernet instead. We will also examine the main drawbacks of Spectrum-X and why some hyperscale enterprises prefer Broadcom's Tomahawk 5.
To illustrate the computational power of a 100,000 GPU cluster, consider that the BF16 FLOPS for GPT-4 training was about 2.15e25 FLOP (21.5 million ExaFLOP), trained on roughly 20,000 A100 GPUs over 90 to 100 days. The peak throughput of this cluster was only 6.28 BF16 ExaFLOP/second. In contrast, on a 100k H100 cluster, this figure would soar to 198/99 FP8/FP16 ExaFLOP/second, marking a 31.5-fold increase in peak theoretical AI training FLOP compared to a 20k A100 cluster.
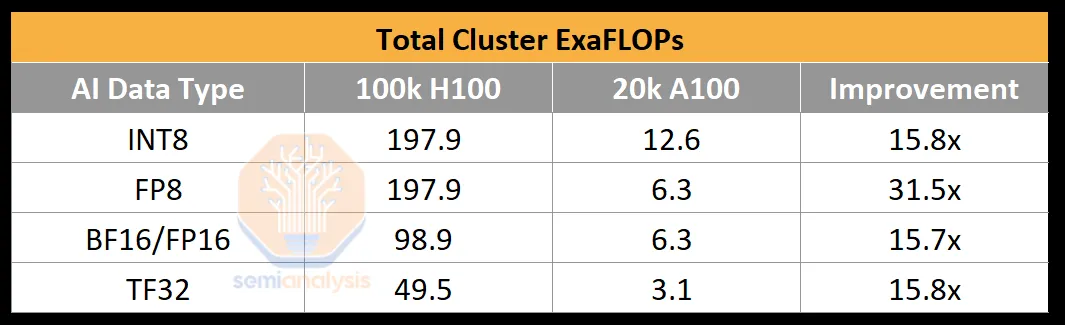
AI labs have achieved up to 35% FP8 model FLOP utilization (MFU) and 40% FP16 MFU in trillion-parameter training runs on the H100. In summary, MFU measures the effective throughput and utilization of peak potential FLOPS, accounting for overhead and various bottlenecks, such as power limitations, communication instability, recomputations, stragglers, and inefficient kernels. A 100,000 H100 cluster could train GPT-4 using FP8 in just four days. After 100 days of training on a 100k H100 cluster, one could achieve approximately 6e26 (600 million ExaFLOP) effective FP8 model FLOP. However, poor hardware reliability can significantly reduce MFU.
Power Challenges
A 100k H100 cluster requires around 150MW of critical IT power. While each GPU consumes only 700W, additional components like CPUs, network interface cards (NICs), and power supply units (PSUs) add approximately 575W per GPU. Beyond the H100 servers, AI clusters also require storage servers, network switches, CPU nodes, optical transceivers, and other items that collectively account for an additional 10% of IT power. Given the 150MW power requirement, the largest national lab supercomputer, El Capitan, only requires 30MW of critical IT power. Compared to industrial systems, government supercomputers pale in comparison.
A primary power challenge is that no single data center building can accommodate a new 150MW deployment. When referencing a 100,000 GPU cluster, it typically implies a campus, not a building. The power demand is so intense that xAI has repurposed an old factory in Memphis, Tennessee, into a data center due to the lack of alternatives.
These clusters are networked via optical transceivers, whose cost scales with their range. Longer-range “single-mode” DR and FR transceivers can reliably transmit signals up to about 2 kilometers but cost 2.5 times more than “multi-mode” SR and AOC transceivers, which support up to about 50 meters. Additionally, campus-level “coherent” 800G transceivers exist, covering over 2 kilometers but at over 10 times the cost.
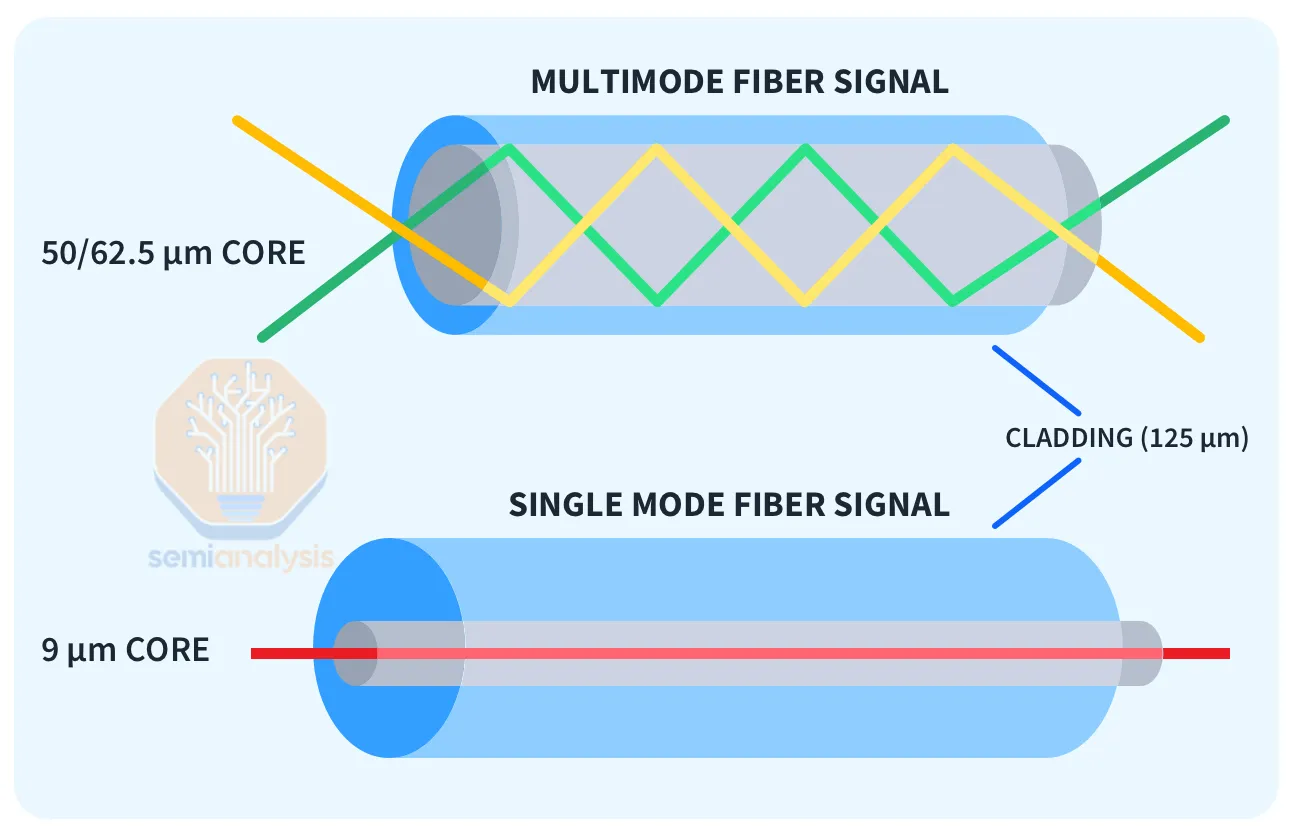
Small H100 clusters typically connect each GPU to every other GPU at 400G speed through one or two layers of switches using only multi-mode transceivers. Large GPU clusters require more switch layers, and the optical components become very costly. The network topology of such clusters varies significantly based on the preferred vendor, current and future workloads, and capital expenditure.
Each design usually includes one or more compute units interconnected with cheaper copper cables or multi-mode transceivers. They then use longer-distance transceivers to interconnect between “islands.” The diagram below shows four compute islands, with higher bandwidth within the islands but lower bandwidth outside. Delivering 155MW in one place is challenging, but we are tracking the construction of over 15 data centers by Microsoft, Meta, Google, Amazon, Bytedance, xAI, Oracle, and others, each providing such extensive space for AI servers and networking.
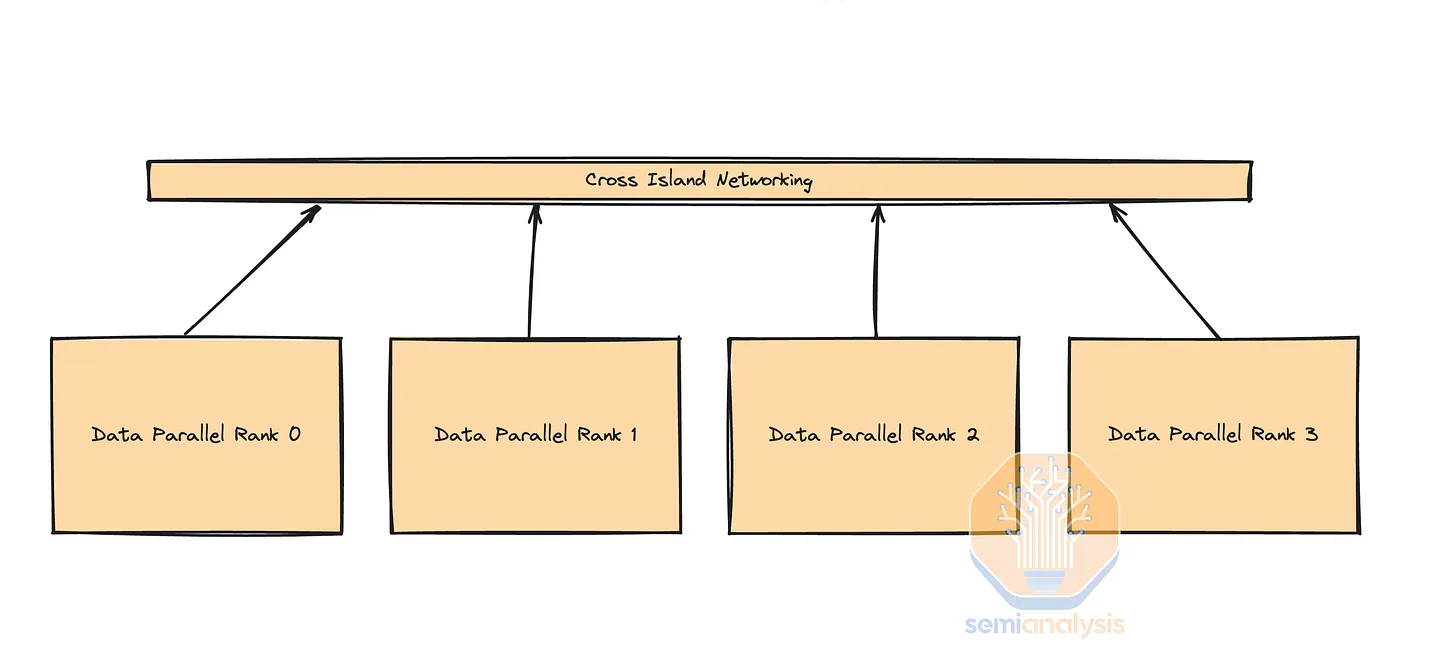
Different customers choose various network topologies based on multiple factors such as data transfer infrastructure, cost, maintainability, power, current and future workloads, etc. Consequently, some customers opt for switches based on Broadcom Tomahawk 5, others stick with InfiniBand, and some choose NVIDIA Spectrum-X. We will delve into the reasons behind these choices below.
Parallelism Review
To understand network design, topology, reliability issues, and checkpoint strategies, we first need to quickly review the three different types of parallelism used in trillion-parameter training: data parallelism, tensor parallelism, and pipeline parallelism. Here, we provide a comprehensive explanation of parallelism, including expert parallelism.
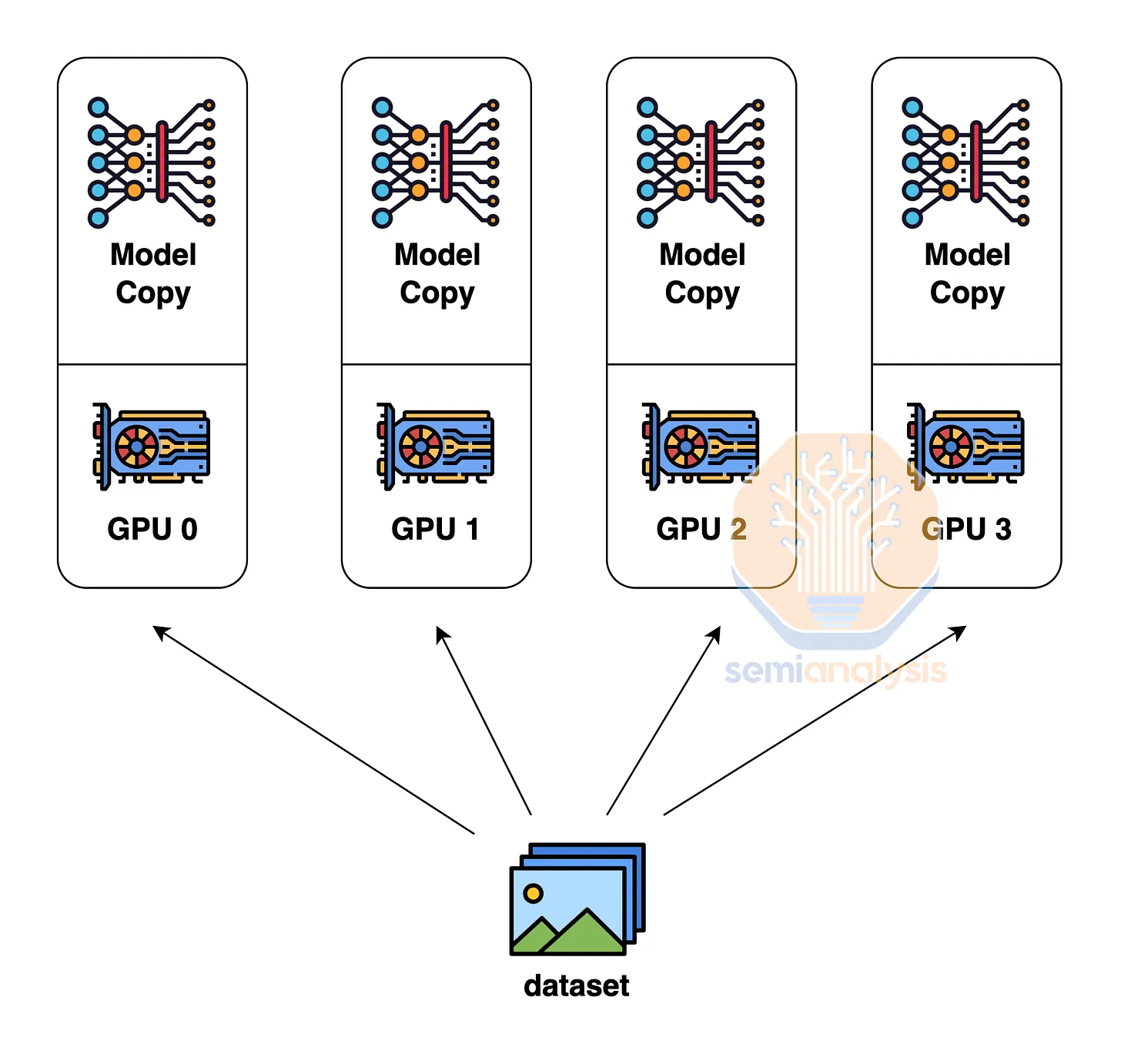
Data parallelism is the simplest form of parallelism, where each GPU holds a complete copy of the model weights, and each GPU (rank) receives a different subset of data. This type of parallelism requires the least communication, as GPUs only need to sum the gradients (all-reduce) between them. However, data parallelism is only effective if each GPU has enough memory to store the entire model weights, activations, and optimizer states. For a model like GPT-4 with 1.8 trillion parameters, the model weights and optimizer states alone require up to 10.8 TB of memory for training.
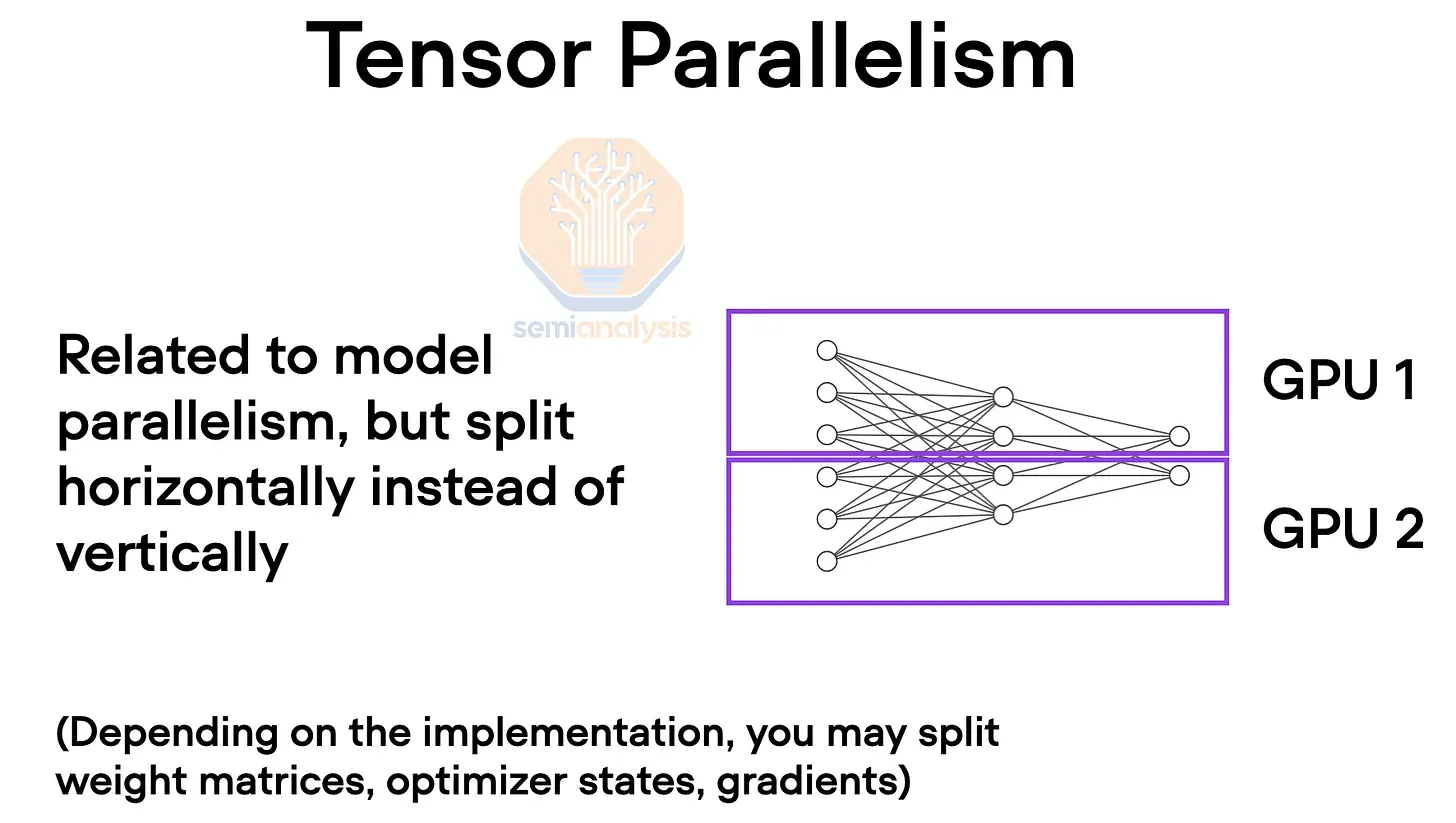
To overcome these memory constraints, we use tensor parallelism. In tensor parallelism, the work and model weights for each layer are typically distributed across multiple GPUs on the hidden dimension. Intermediate work is exchanged multiple times between devices via all-reduce, involving self-attention, feed-forward networks, and layer normalization for each layer. This requires high bandwidth and very low latency. Essentially, every GPU within a domain works with every other GPU on each layer as if they were part of a giant GPU. Tensor parallelism reduces the total memory used by each GPU by the number of tensor parallelism ranks. For example, using eight tensor parallelism ranks on NVLink is common, reducing the memory each GPU uses by eight.
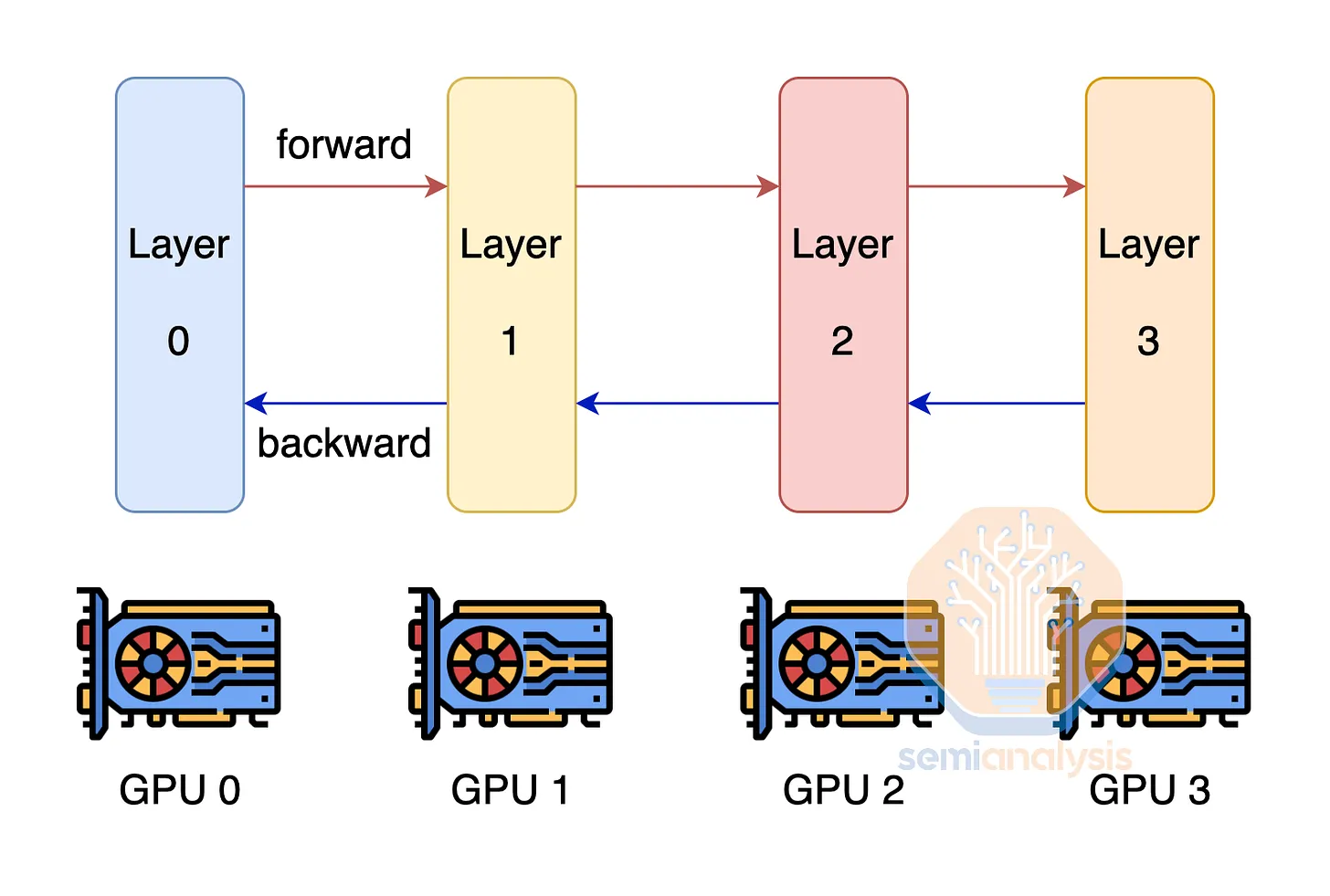
Another technique to overcome the challenge of insufficient GPU memory to hold model weights and optimizer states is pipeline parallelism. With pipeline parallelism, each GPU only has a subset of the layers and computes only those layers, passing the output to the next GPU. This technique reduces the memory required by the number of pipeline parallelism ranks. Pipeline parallelism has significant communication requirements, though not as high as tensor parallelism.
To maximize model FLOP utilization (MFU), companies often combine all three forms of parallelism into 3D parallelism. Tensor parallelism is applied to GPUs within an H100 server, pipeline parallelism is used between nodes within the same Island, and data parallelism, having the lowest communication volume, is used between Islands due to the slower inter-Island network.
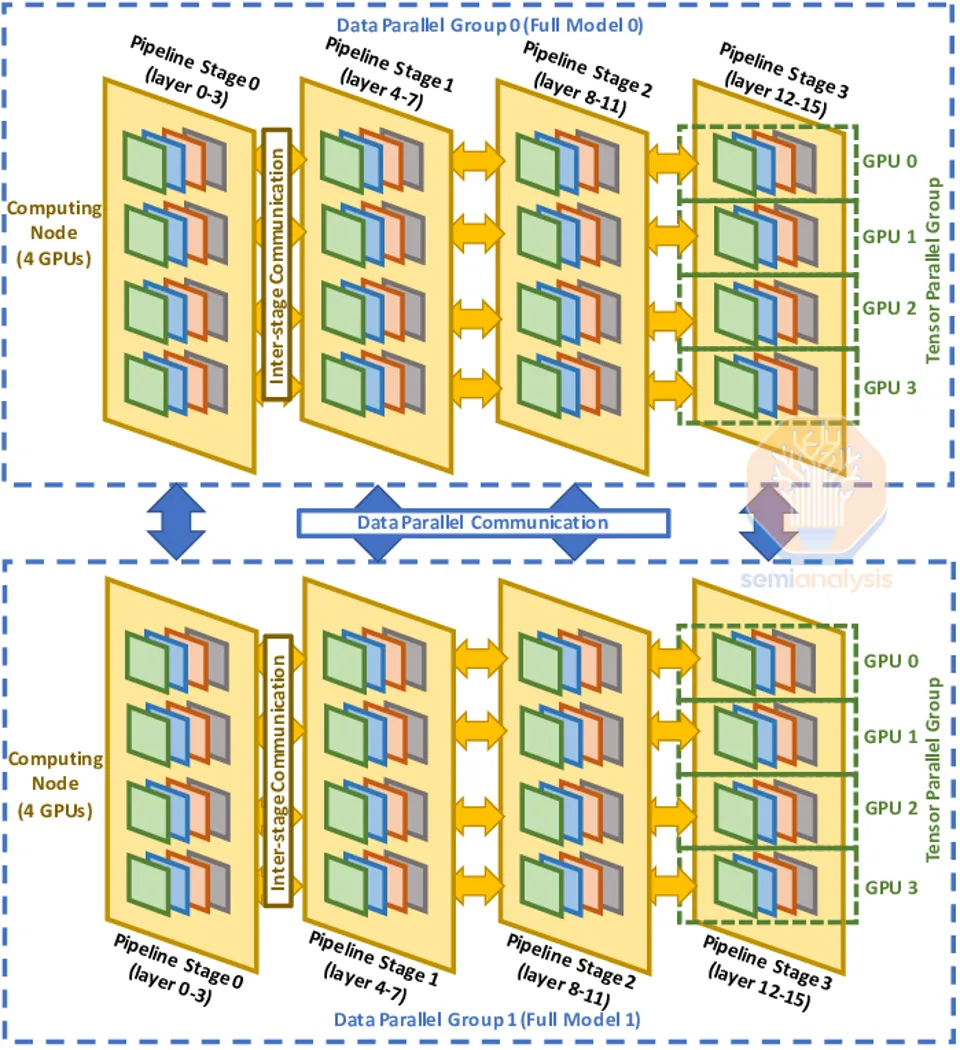
Technologies like FSDP are common at a small GPU world scale for very large models but do not work well. They are actually incompatible with pipeline parallelism.
Network Design Considerations
When designing a network, parallelism schemes are considered. Connecting each GPU to every other GPU at maximum bandwidth in a fat-tree topology would be prohibitively expensive, requiring four layers of switches. Since each additional network layer requires intermediate optical components, the cost of optics would soar.
As a result, no one deploys a full fat-tree architecture for large GPU clusters. Instead, they rely on creating compute Islands with full fat-tree architecture within the Island while having less bandwidth between Islands. There are various ways to achieve this, but most companies opt for "oversubscription" at the top layer of the network. For example, Meta's previous generation GPU cluster architecture supports up to 32,000 GPUs across eight Islands, each with full fat bandwidth internally, and another layer of switches on top with a 7:1 oversubscription rate. The network speed between Islands is seven times slower than within Islands.
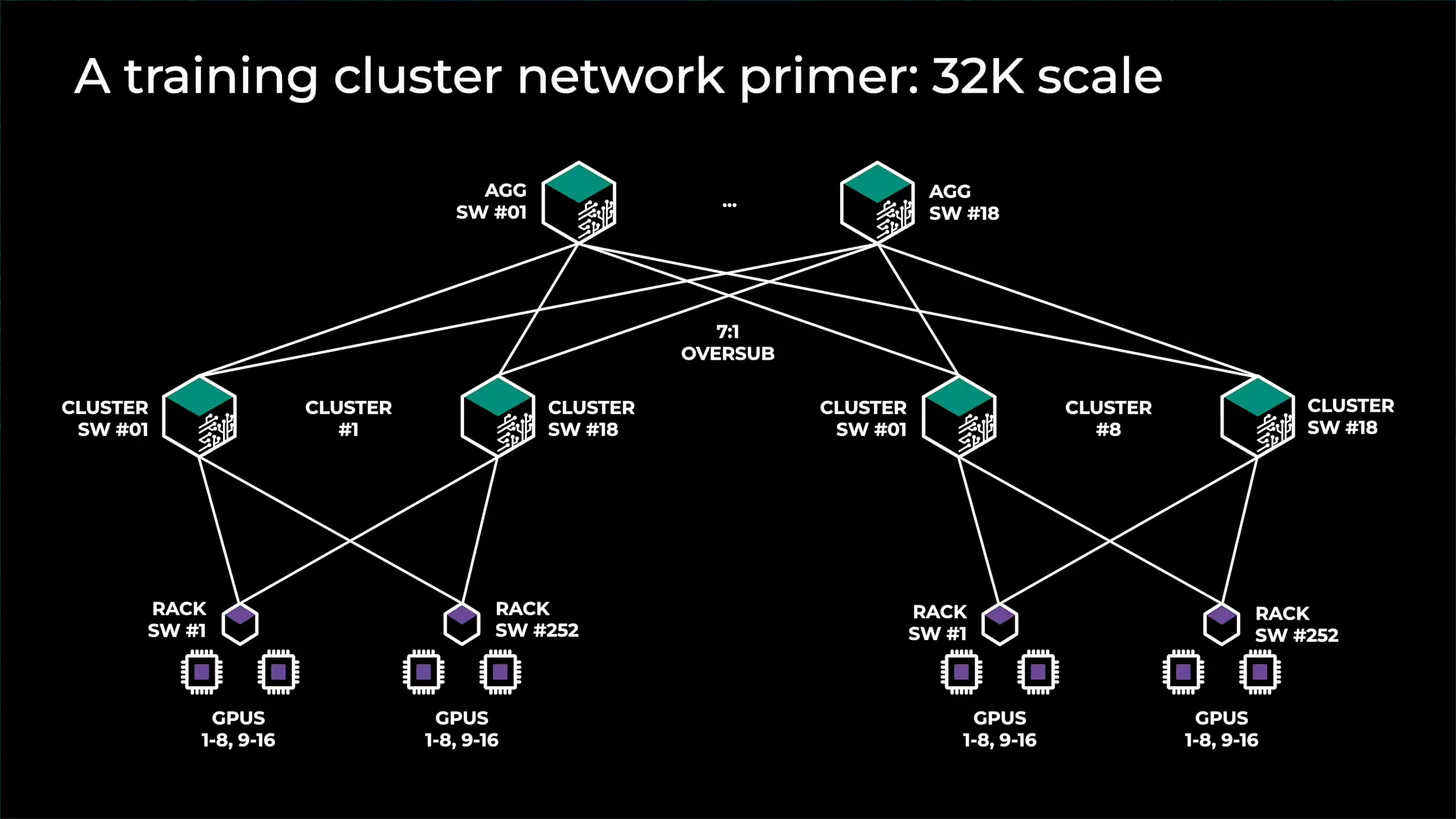
GPU deployments feature multiple networks: front-end, back-end, and extension (NVLink). Different parallel schemes may run on each network. The NVLink network might be the only one fast enough to meet tensor parallelism bandwidth requirements. The back-end network usually handles most other parallel types, but with oversubscription, it typically only supports data parallelism.
Some setups do not even have oversubscribed top-layer bandwidth Islands. Instead, they transition inter-Island communication from the back-end network to the front-end network.
Mixed InfiniBand and Front-End Ethernet Structures
A large company uses front-end Ethernet to train across multiple InfiniBand Islands due to the significantly lower cost of front-end networks and the ability to utilize existing data center campus networks between buildings and areas.
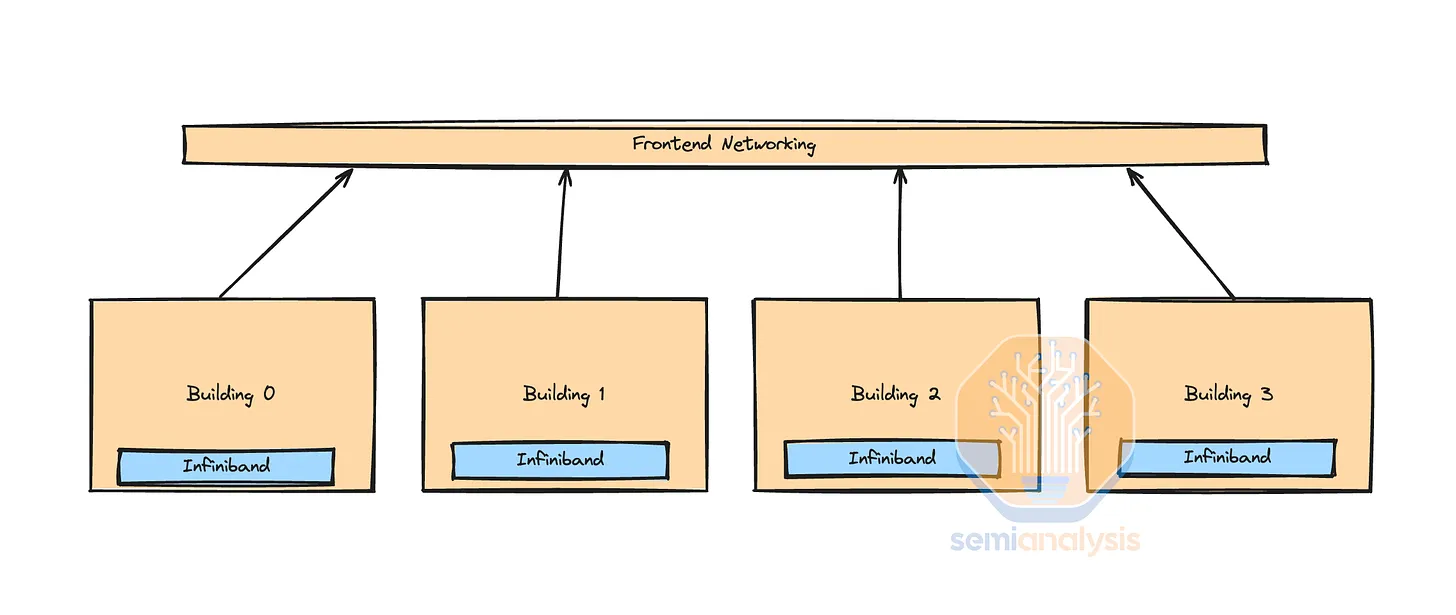
Unfortunately, as model sizes grow faster with sparse techniques like MoE, the communication load on the front-end network increases. This trade-off must be carefully optimized; otherwise, the front-end network bandwidth might grow so large that it matches the back-end network's cost.
Google, for example, exclusively uses front-end networks for multi-TPU pod training runs. Their "compute fabric," called ICI, scales up to 8,960 chips using expensive 800G optics and optical circuit switches to connect each 64-TPU water-cooled rack. Hence, Google compensates by making the TPU front-end network stronger than most GPU front-end networks.
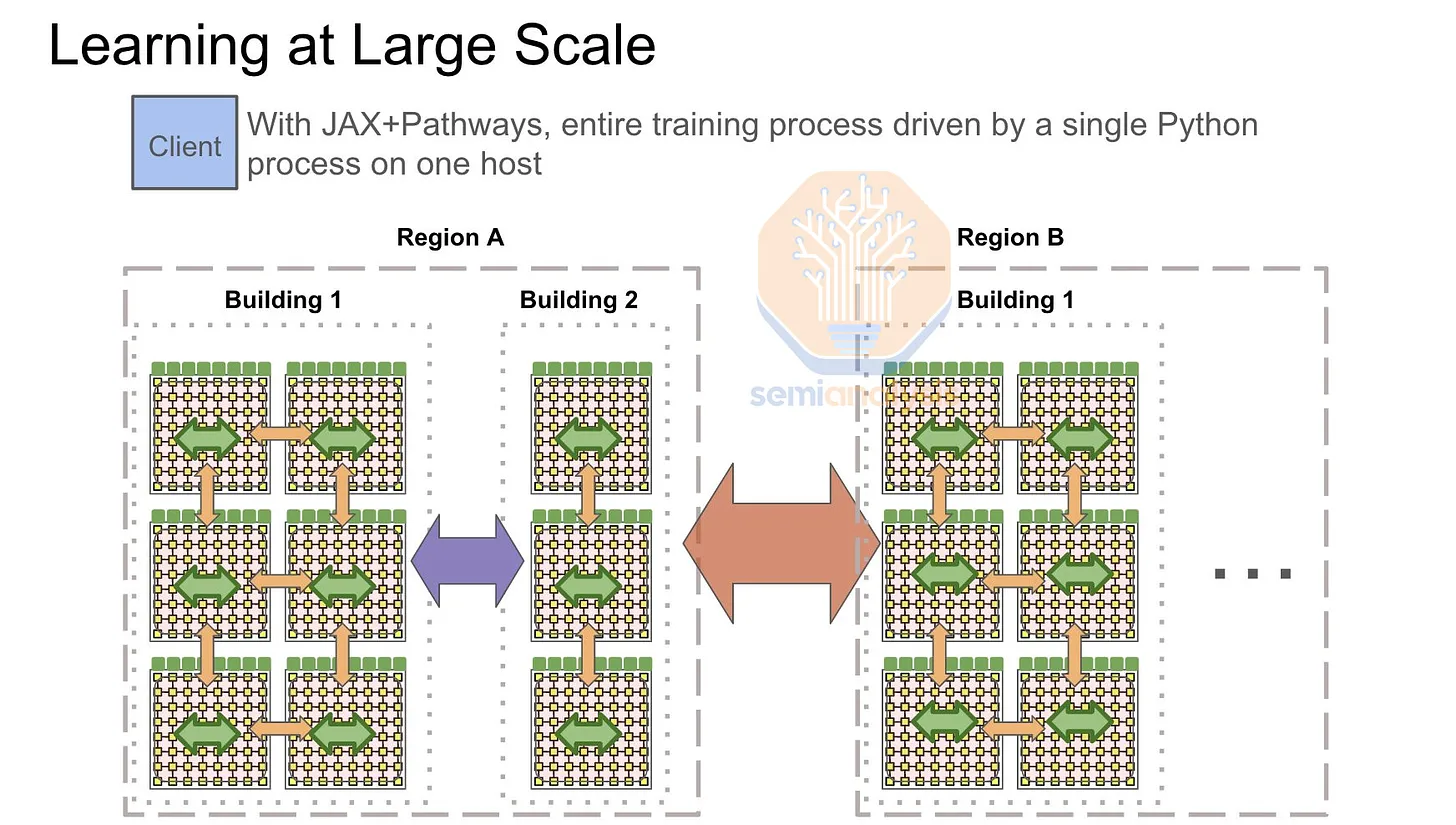
During training, the front-end network must execute network topology-aware global all-reduces between Islands. Initially, each pod or Island performs local reduce-scatter within the pod InfiniBand or ICI network, summing gradient subparts for each GPU/TPU. Next, cross-pod all-reduce is performed between host ranks using the front-end Ethernet network, and finally, each pod executes a pod-level all-gather.
The front-end network is also responsible for data loading. As we shift towards multi-modal image and video training data, front-end network demands will grow exponentially. In this scenario, front-end network bandwidth will compete between loading large video files and performing all-reduces. Additionally, irregular storage network traffic increases straggler issues, slowing the entire all-reduce process and hindering predictive modeling.
An alternative is a four-layer InfiniBand network with a 7:1 oversubscription rate, containing four pods with 24,576 H100 each, in a non-blocking three-layer system. This setup offers greater future bandwidth flexibility, as adding more optical transceivers between switches from Building A to Building B is easier than upgrading every chassis in the cluster's front-end network NICs from 100G to 200G.
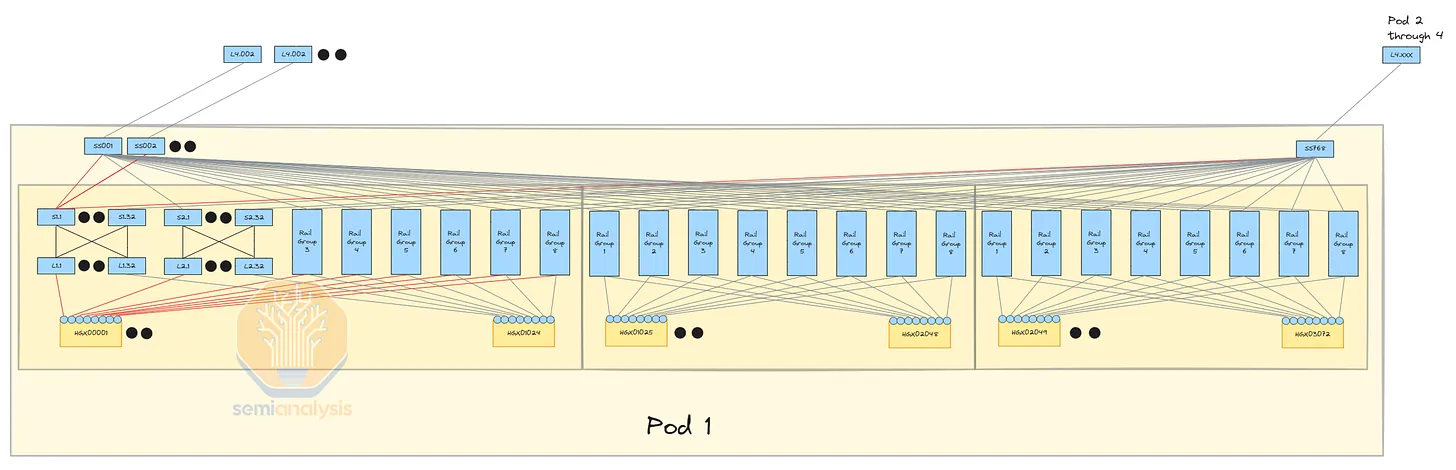
This configuration creates a more stable network pattern, allowing the front-end network to focus on data loading and checkpointing, while the back-end network handles GPU-to-GPU communication. It also addresses straggler issues. However, a four-layer InfiniBand network is costly due to the additional switches and transceivers required.
Rail-Optimized vs. Mid-Rack Designs
To enhance maintainability and increase the use of copper networks (<3m) and multi-mode networks (<50m), some customers opt for mid-rack designs instead of NVIDIA's recommended rail-optimized design.
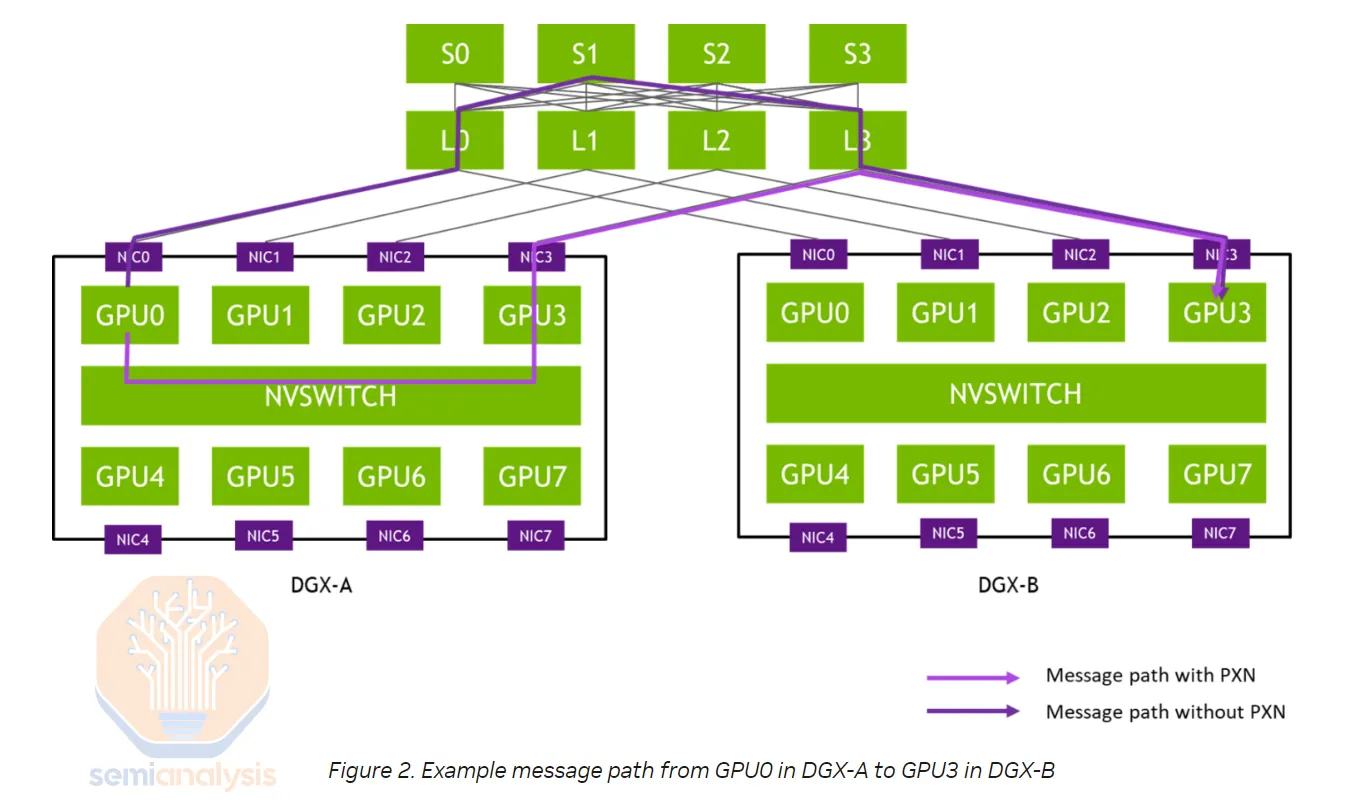
Rail-optimized design connects each H100 server to eight different leaf switches (instead of all connecting to a central rack switch), enabling each GPU to communicate with farther GPUs with just one switch hop. This improves the performance of all collective operations in real-world applications. Collective communication is heavily used in MoE expert parallelism.
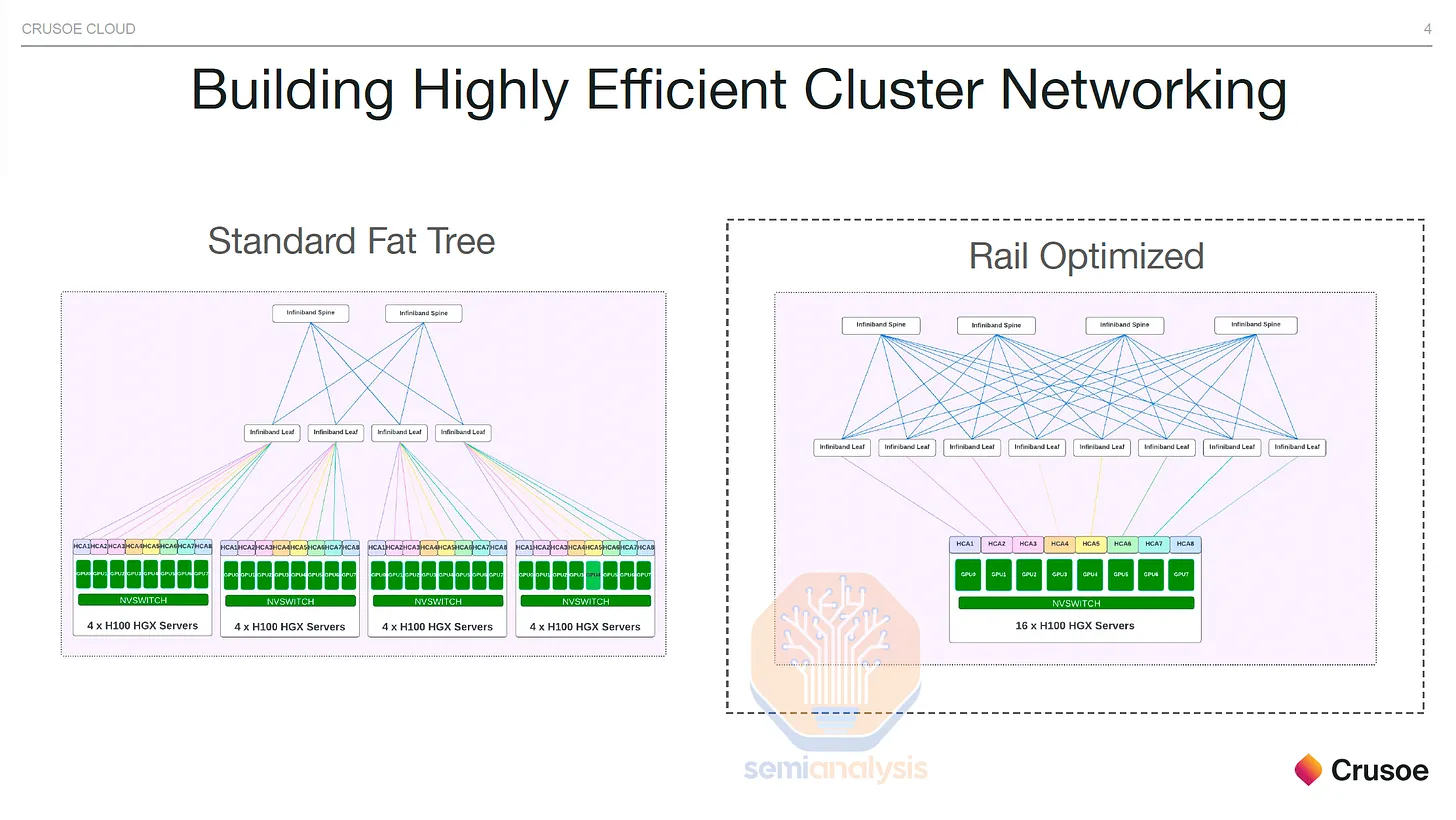
The downside of rail-optimized design is the need to connect to different leaf switches at varying distances, rather than connecting to a central rack switch close to all eight GPUs. While passive direct-attach cables (DACs) and active cables (AECs) can be used when switches are within the same rack, rail-optimized designs often require fiber optics due to distance. Additionally, the leaf-to-spine distance may exceed 50m, necessitating single-mode optical transceivers.
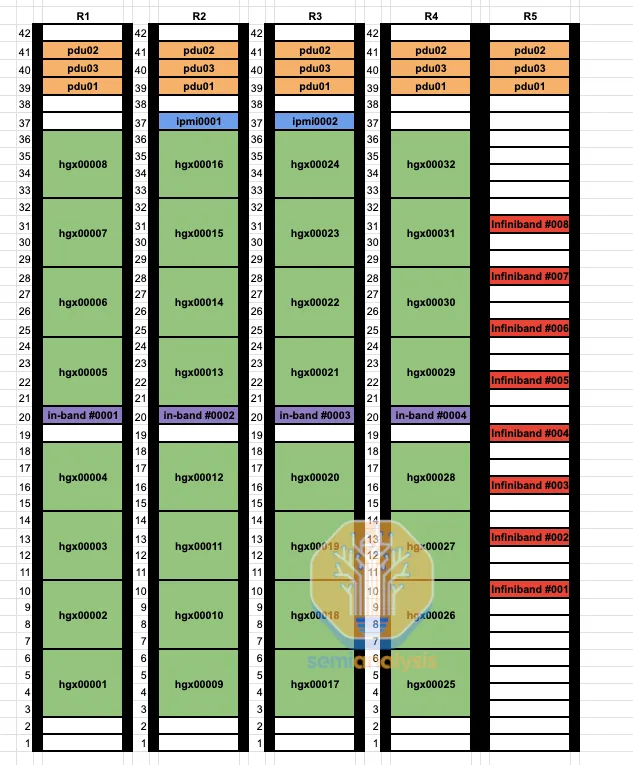
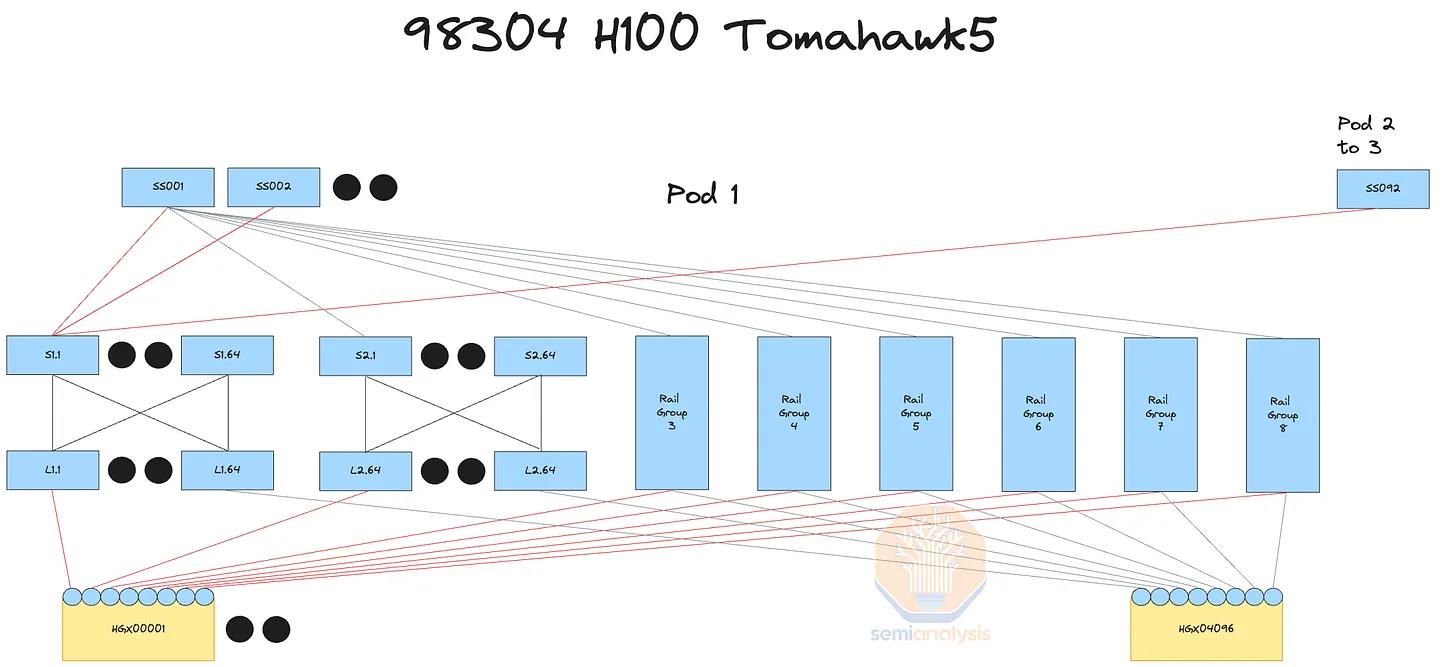
By using a non-rail-optimized design, you can replace 98,304 optical transceivers with cheaper direct-attached copper cables, making 25-33% of your GPU fabric copper. As seen in the rack diagram below, leaf switches are now mid-rack, allowing each GPU to use DAC copper cables, rather than connecting up to cable trays and across nine racks to dedicated rail-optimized leaf switch racks.
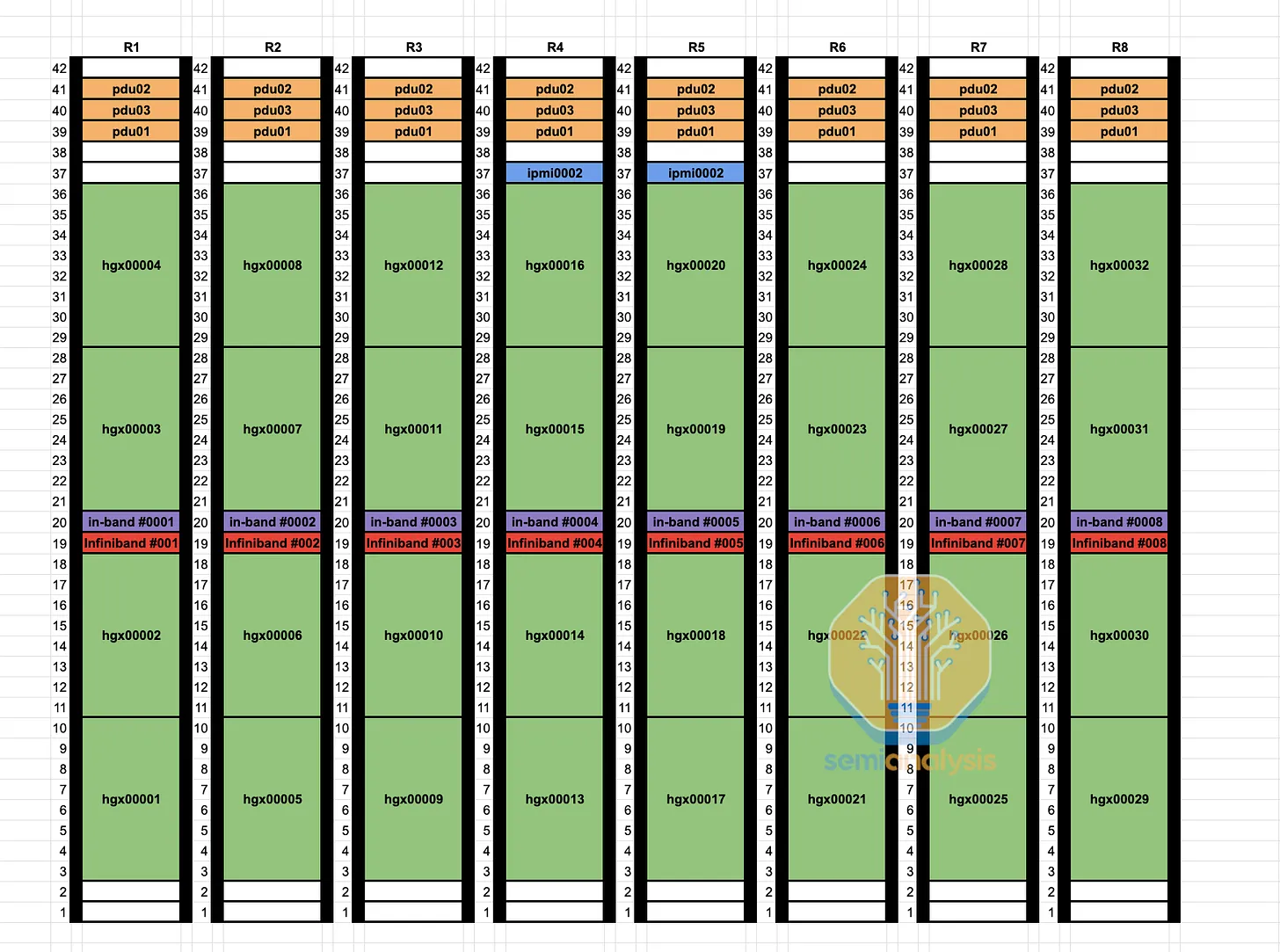
Compared to fiber optics, DAC copper cables run cooler, consume less power, and are cheaper. This reduces jitter (intermittent network link failures) and faults, which are major issues for high-speed interconnects using fiber optics. With DAC copper cables, Quantum-2 IB spine switch power consumption is 747 watts, while using multi-mode optical transceivers increases it to 1,500 watts.
Additionally, the initial wiring of rail-optimized designs is extremely time-consuming for data center technicians, with link ends up to 50m apart and not in the same rack. In contrast, mid-rack designs place leaf switches and all GPUs connected to them in the same rack. This allows integration factory testing of compute node to leaf switch links since they are all within the same rack.
Reliability and Recovery
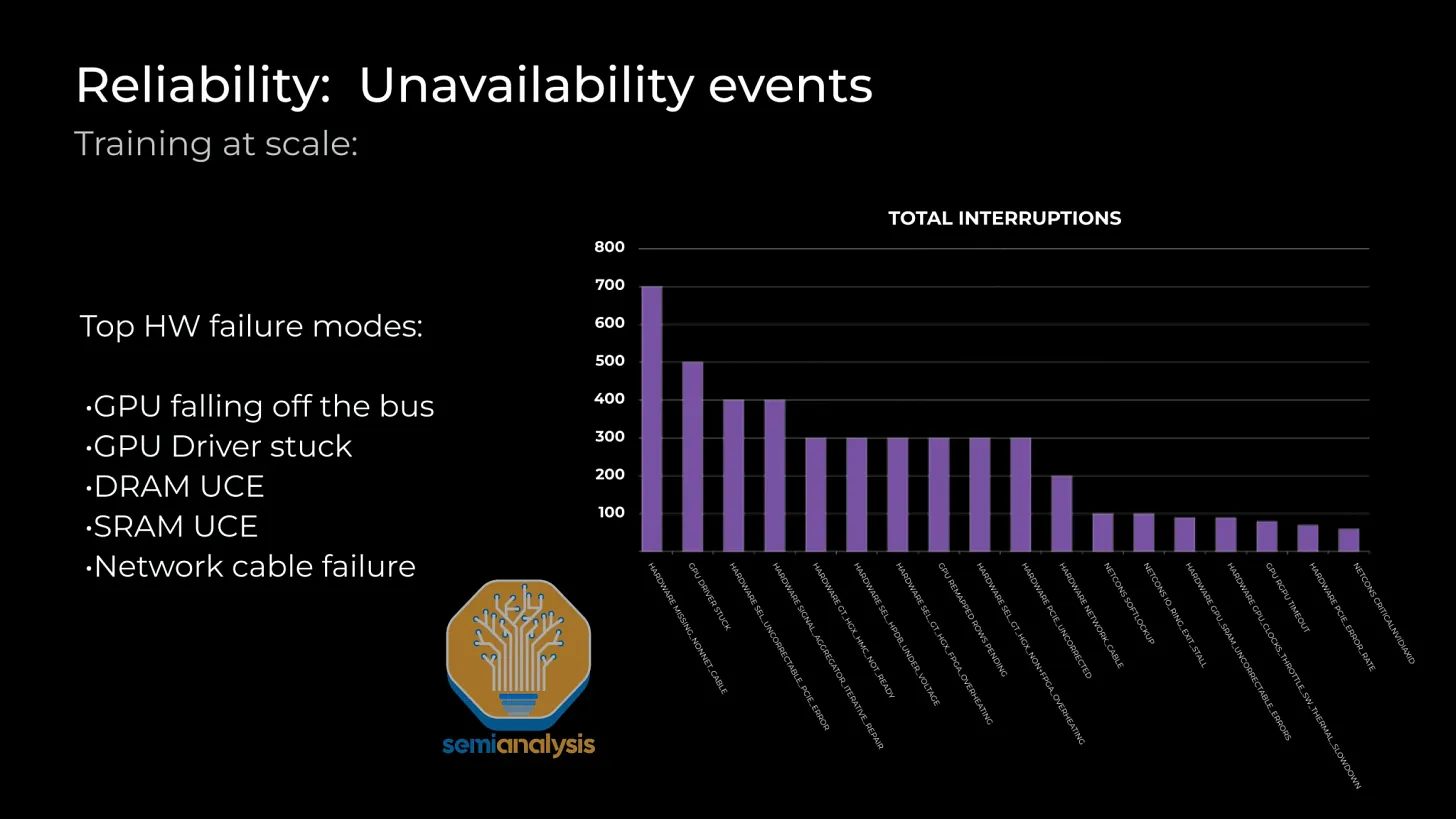
Reliability is a crucial operational issue for these mega clusters due to the synchronous nature of cutting-edge training techniques. Common reliability problems include GPU HBM ECC errors, GPU driver stalls, optical transceiver failures, NIC overheating, and more. Nodes frequently experience failures or errors.
To minimize downtime and continue training, data centers must keep hot standby nodes and cold standby components on-site. When a failure occurs, the preferred approach is not to halt the entire training run but to swap in a hot standby node and continue training. Most downtime for these servers involves power cycling/rebooting the node and addressing any issues.
However, simple reboots do not solve all problems, and many cases require physical diagnostics and equipment replacement by data center technicians. Ideally, this takes a few hours, but it can take days to reintegrate a damaged node into a training run. Damaged nodes and hot standby nodes, though theoretically providing FLOPS, do not actively contribute to the model.
During model training, frequent checkpoints must be set to CPU memory or NAND SSDs to guard against errors like HBM ECC errors. When an error occurs, model and optimizer weights must be reloaded from slower memory layers, resuming training from the last checkpoint. Fault-tolerant training techniques, like Oobleck, offer application-level methods to handle GPU and network failures.
Unfortunately, frequent checkpoints and fault-tolerant training techniques hurt overall MFU. The cluster must continually pause to save current weights to persistent memory or CPU memory. Reloading from checkpoints, typically saved every 100 iterations, means losing up to 99 steps of work. In a 100k cluster, if each iteration takes 2 seconds, a failure at the 99th iteration can result in losing up to 229 GPU days of work.
Another recovery method involves RDMA copying weights from other GPUs to the standby node via the back-end fabric. Given a 400Gbps back-end GPU fabric and 80GB HBM memory per GPU, copying weights takes about 1.6 seconds. This approach limits loss to one step, with more GPUs holding the latest weight copies, incurring only 2.3 GPU days of computation plus another 1.85 GPU days for RDMA copying.
Most leading AI labs have implemented this technique, but many smaller companies still rely on the cumbersome, slow method of checkpoint restart for all failures due to its simplicity. Memory-reconstruction fault recovery can add several percentage points to MFU for large-scale training runs.
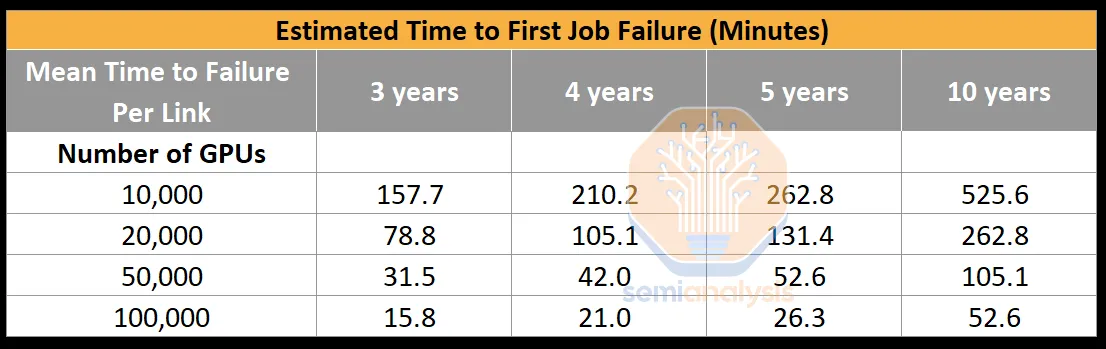
Infiniband/RoCE link failures are common issues. Even with a mean time between failures of 5 years for each NIC to leaf switch link, the first job failure on a new, normal cluster occurs in just 26.28 minutes. Without memory-reconstruction fault recovery, optical failures in a 100,000 GPU cluster mean more time restarting training than advancing the model.
Because each GPU connects directly to a ConnectX-7 NIC via PCIe switches, there is no fault tolerance at the network architecture level, requiring failure handling in user training code, increasing code complexity. This is a major challenge for current NVIDIA and AMD GPU network architectures, as a NIC failure leaves no alternate communication path. Since LLMs use tensor parallelism within nodes, any NIC, transceiver, or GPU failure deems the entire server offline.
Significant efforts are underway to make networks reconfigurable and less fragile. This is crucial because the current state means a single GPU or optical failure can cripple an entire GB200 NVL72, a multimillion-dollar 72 GPU rack, far more disastrous than an eight-GPU server failure.
NVIDIA has acknowledged this major issue and added a dedicated engine to improve Reliability, Availability, and Serviceability (RAS). We believe the RAS engine analyzes chip-level data like temperature, recovered ECC retries, clock speeds, and voltage to predict potential chip failures and alert data center technicians. This enables proactive maintenance, such as using higher fan speed profiles for reliability or taking servers offline for further inspection during maintenance windows. Additionally, before starting training jobs, each chip's RAS engine will perform comprehensive self-tests, like running matrix multiplications with known results to detect silent data corruption (SDC).
Cost Optimization with Cedar-7
Microsoft/OpenAI and other customers are optimizing costs by using Cedar Fever-7 network modules instead of eight PCIe form-factor ConnectX-7 NICs per server. One of the primary benefits of using Cedar Fever modules is the reduction of OSFP cages to four, rather than eight, enabling the use of dual-port 2x400G transceivers on the compute node side (not just the switch side). This reduces the number of transceivers connecting GPUs to leaf switches from 98,304 to 49,152.

By halving the GPU-to-leaf switch links, this also helps estimate the first job failure time. We estimate the mean time between failures (MTBF) for each dual-port 2x400G link to be four years (compared to five years for single-port 400G links), improving the estimated first job failure time to 42.05 minutes, significantly better than the 26.28 minutes without Cedar-7 modules.

Spectrum-X and NVIDIA
A 100k H100 cluster using NVIDIA Spectrum-X Ethernet is being deployed and will be operational by the end of the year.
There are multiple advantages of Spectrum-X over InfiniBand in large networks. Besides performance and reliability benefits, Spectrum-X offers substantial cost advantages. Each SN5600 switch in Spectrum-X has 128 400G ports, whereas the InfiniBand NDR Quantum-2 switch has only 64 400G ports. Note that Broadcom's Tomahawk 5 switch ASIC also supports 128 400G ports, putting the current generation of InfiniBand at a disadvantage.
A fully interconnected 100k cluster can be a three-tier instead of a four-tier network. Using four tiers instead of three means needing 1.33 times more transceivers. Due to the lower radix of Quantum-2 switches, the maximum number of fully interconnected GPUs in a 100k cluster is limited to 65,536 H100s. The next-generation InfiniBand switch, Quantum-X800, addresses this with 144 800G ports, designed for use with NVL72 and NVL36 systems, but is not expected to see much use in B200 or B100 clusters. Although using Spectrum-X avoids needing four tiers, saving costs, the unfortunate downside is that you still need to purchase expensive transceivers from NVIDIA's LinkX product line, as other transceivers might not work or are not certified by NVIDIA.
Advantages and Disadvantages of Spectrum-X
Spectrum-X's main advantage over other vendors is first-class support from NVIDIA libraries like NCCL and Jensen, pushing you to the front of the queue to be one of the first customers for their new product lines. In contrast, using Tomahawk 5 chips requires extensive internal engineering to optimize your network with NCCL for maximum throughput.
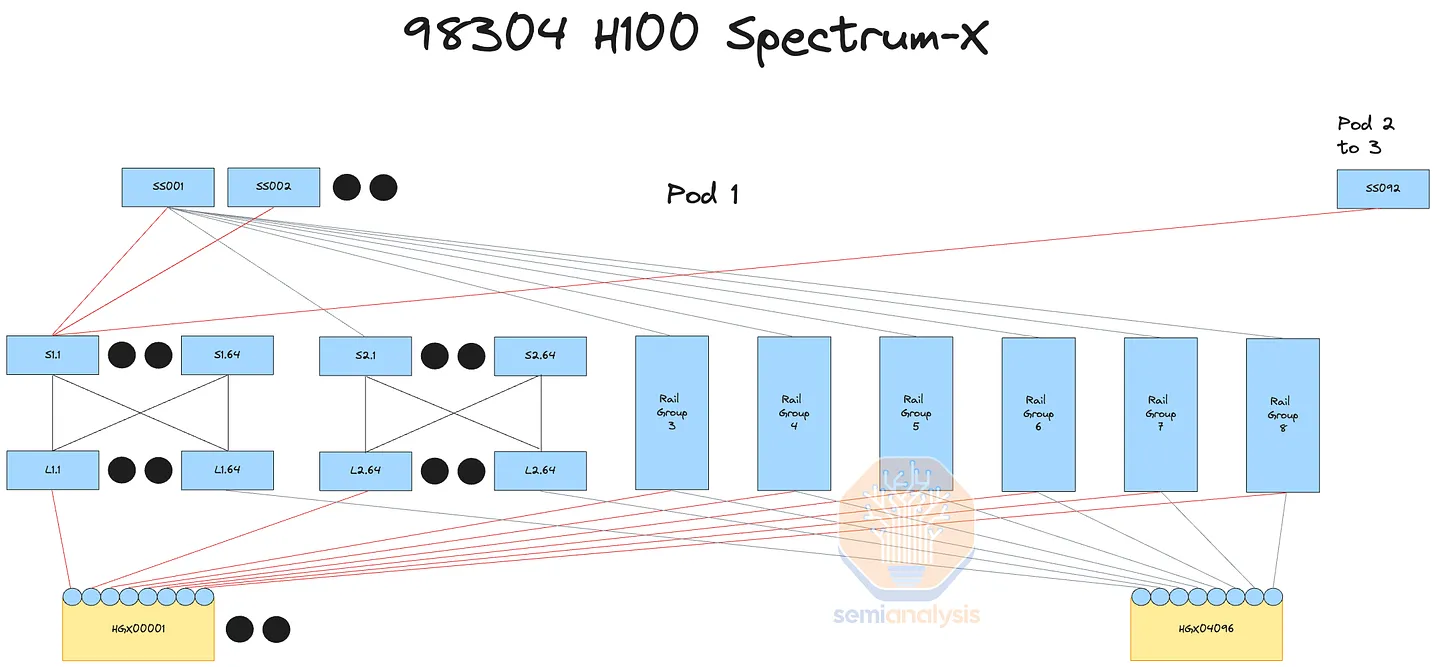
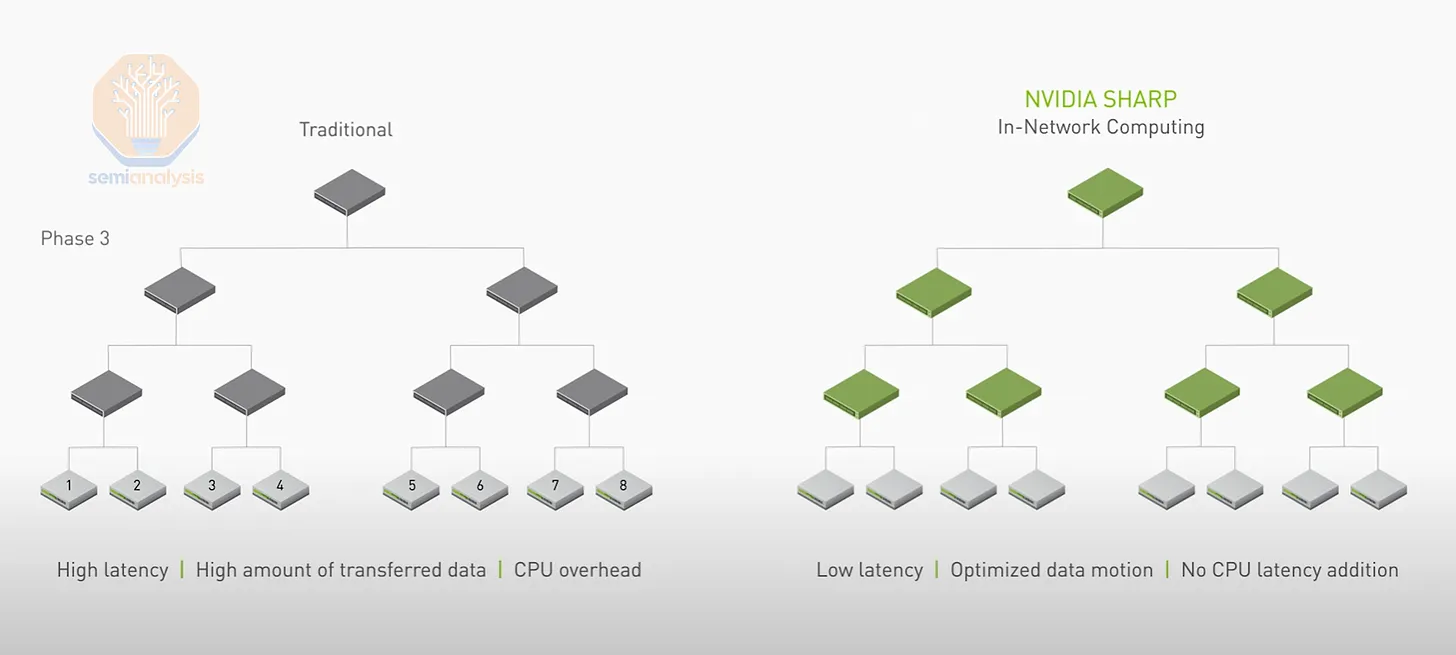
A downside of using Ethernet instead of InfiniBand as the GPU fabric is the current lack of support for SHARP in-network reduction. SHARP works by having network switches perform the summation calculations for each GPU, theoretically doubling network bandwidth by halving the number of sends and writes each GPU must perform.
Another disadvantage of Spectrum-X is that for the first generation 400G Spectrum-X, NVIDIA uses Bluefield-3 instead of ConnectX-7 as a stop-gap solution. For future generations, we expect ConnectX-8 to pair perfectly with 800G Spectrum-X. For hyperscale production, the price difference between Bluefield-3 and ConnectX-7 cards is about $300 ASP, with Bluefield-3 consuming 50 watts more power. This means an additional 400W per node, reducing the "intelligence per picojoule" of the entire training server. Compared to deployments with the exact same network architecture using Broadcom Tomahawk 5, the data center deploying Spectrum-X now needs an extra 5MW to deploy 100,000 GPUs.
Broadcom Tomahawk 5
To avoid paying a hefty NVIDIA tax, many customers are deploying switches based on Broadcom's Tomahawk 5. Each Tomahawk 5-based switch has the same number of ports as Spectrum-X SN5600 switches, with 128 400G ports. With excellent network engineers, your company can achieve similar performance. Additionally, you can purchase generic transceivers and copper cables from any global supplier and mix and match them.
Most businesses work directly with ODMs like Celestica, using Broadcom-based switch ASICs, and transceivers from companies like Innolight and Eoptolink. Considering switch costs and generic transceiver costs, Tomahawk 5 is much cheaper than NVIDIA InfiniBand and also cheaper than NVIDIA Spectrum-X.
The drawback is the engineering capability required to patch and optimize Tomahawk 5's NCCL communication collectives. NCCL communication collectives are optimized out-of-the-box only for NVIDIA Spectrum-X and NVIDIA InfiniBand. The good news is that if you have $4 billion for a 100k cluster, you likely have sufficient engineering talent to patch NCCL and write optimizations. While software is hard, and NVIDIA is always on the cutting edge, we generally expect every hyperscaler to make these optimizations and abandon InfiniBand.
Enhancing AI Infrastructure with NADDOD
In the rapidly evolving world of AI, having reliable and high-performance networking solutions is crucial. NADDOD stands out as a leader in this field, offering a comprehensive range of optical transceivers and networking solutions that are essential for building robust and scalable AI infrastructure.
NADDOD’s Key Strengths:
- High-Speed Products: NADDOD specializes in high-speed InfiniBand and RoCE solutions, ensuring seamless and efficient data transfer.
- Variety of Packaging Forms: Catering to diverse needs, NADDOD provides products in various packaging forms to suit different data center configurations.
- Inventory Availability: With a large inventory, NADDOD ensures that products are readily available to meet urgent requirements.
- Short Delivery Cycles: NADDOD’s efficient logistics enable quick delivery, minimizing downtime and ensuring project timelines are met.
- 100% Product Verification: Every product undergoes rigorous testing before shipping, ensuring top-notch quality and reliability.
- Timely Service: NADDOD offers prompt and effective customer service, ensuring that any issues are quickly resolved to keep your operations running smoothly.
Visit NADDOD’s website to learn more!


 800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module
800GBASE-2xSR4 OSFP PAM4 850nm 50m MMF Module- 1The Evolution of 400G, 800G, and 1.6T Optical Modules
- 2DAC's Growing Importance in High-Performance AI Networking
- 3Next-Gen Data Centers: Embracing Liquid Cooling
- 4Introduction to Open-source SONiC: A Cost-Efficient and Flexible Choice for Data Center Switching
- 5OFC 2025 Recap: Key Innovations Driving Optical Networking Forward






